type
status
date
slug
summary
tags
category
icon
password
Doc2X 产品简介
Doc2X 是一款专为开发者设计的强大文档解析产品,能够将PDF、图片等多种格式的文档精准转换为 Markdown、LaTeX、HTML、Word等结构化或半结构化格式。
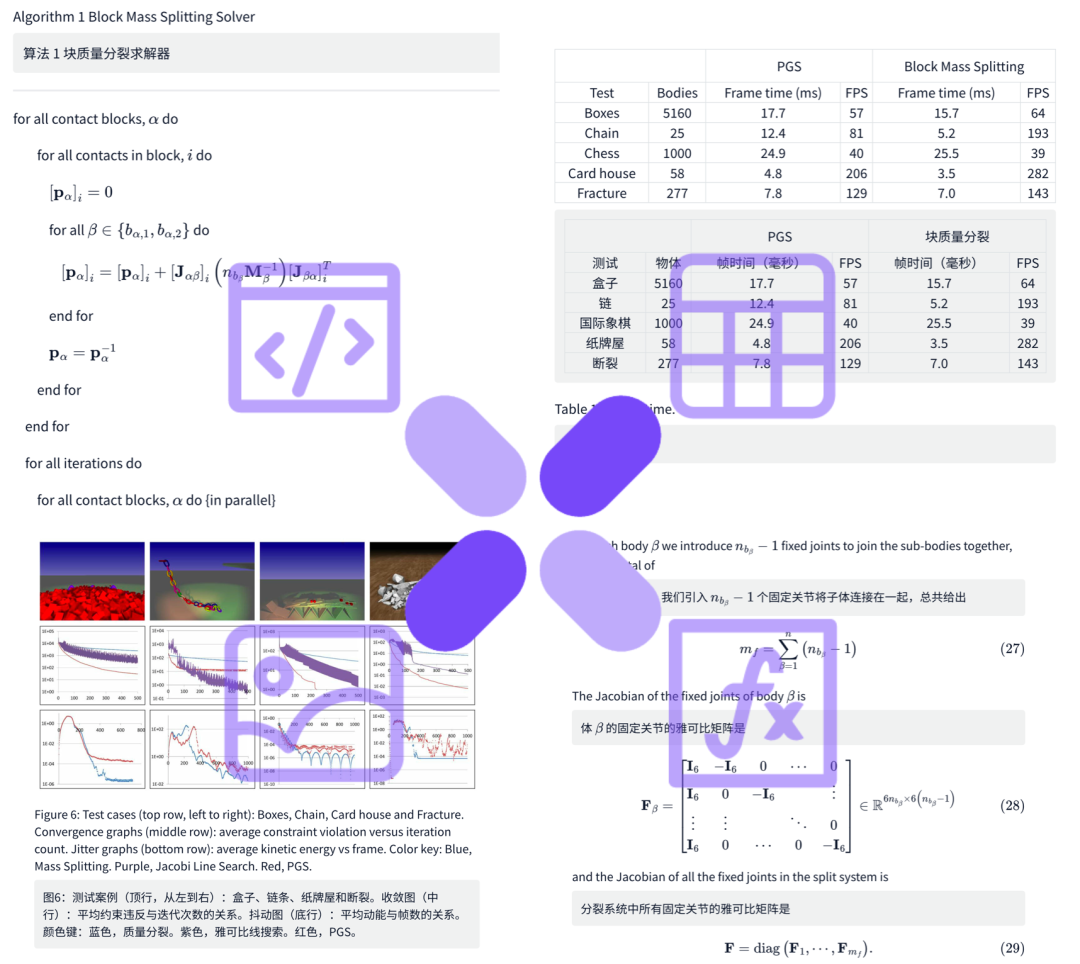
Doc2X 有以下核心优势:
- 全方位格式支持:从PDF快速转化为Word、Docx、LaTeX、HTML、Markdown多种格式,灵活满足不同场景的需求。
- 对照编辑与校对:支持在转换前对照PDF原文,快速跳转编辑与比对,确保转换结果的准确性与完整性。
- 高保真还原:无论是学术论文中的公式、表格、图片,还是企业文档中的图示与排版结构,都能在目标格式中尽可能保留原貌。
- 快速批量转换:支持处理大量PDF文件,一键批量转换,多线程加速,大幅提升工作效率。
- 多学科领域适配:适用于学术科研、教育出版、企业办公、技术文档和Web内容创建等多元应用场景。
文档一键解析
Doc2X在线体验地址:https://doc2x.noedgeai.com
Doc2X 支持解析 PDF 文件和 JPG、PNG、Webp 等多种类型的文字,同时支持 Doubao、gpt、deepseek、qwen 等多种主流大模型进行解析。
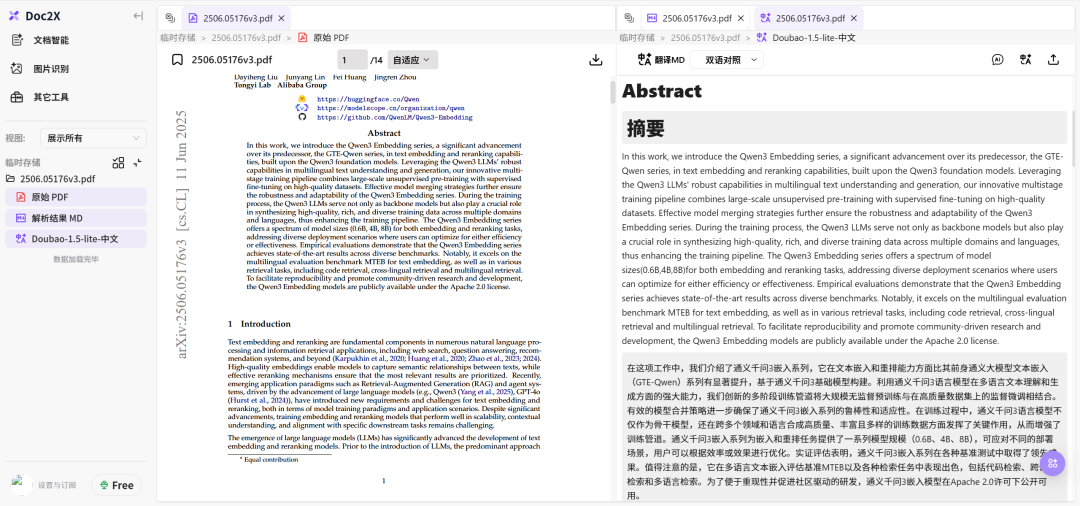
上传PDF文件,可以解析成md格式的结构化文本,同时支持双语对照查看。
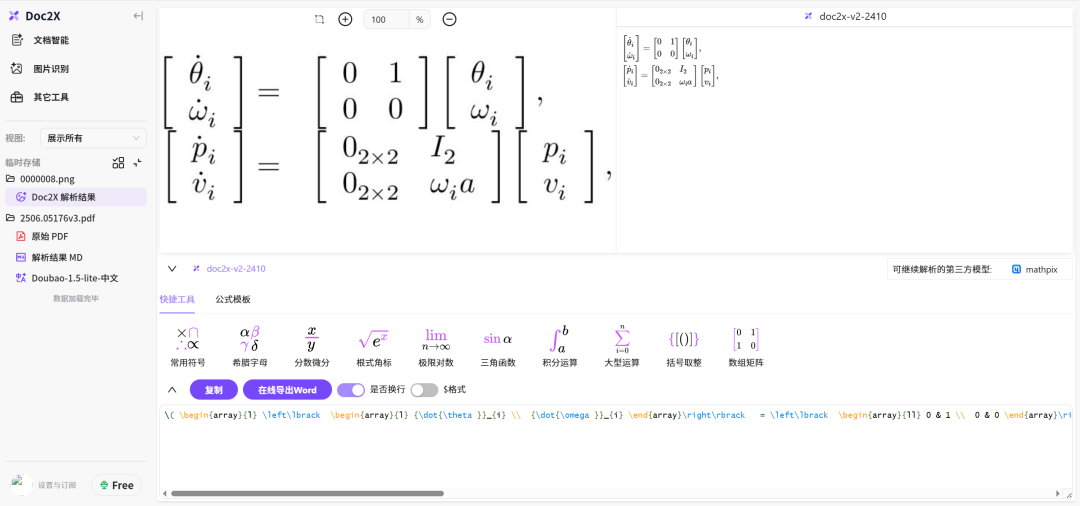
上传图像文件,会自动解析文本和公式,同时支持对公式的二次编辑,非常方便。
知识库构建与问答
Doc2X 支持多种类型的元素解析,同时支持复杂表格解析,可搭配其它 ima、CherryStudio、Coze等其它知识库问答平台进行知识库构建和问答。
下面以 ima 为例,介绍如何构建知识库并实现问答交互。
首先在 Doc2X 解析文件,如下图所示,其可以将复杂的表格 PDF 文件解析成大语言模型能读懂的结构化格式。
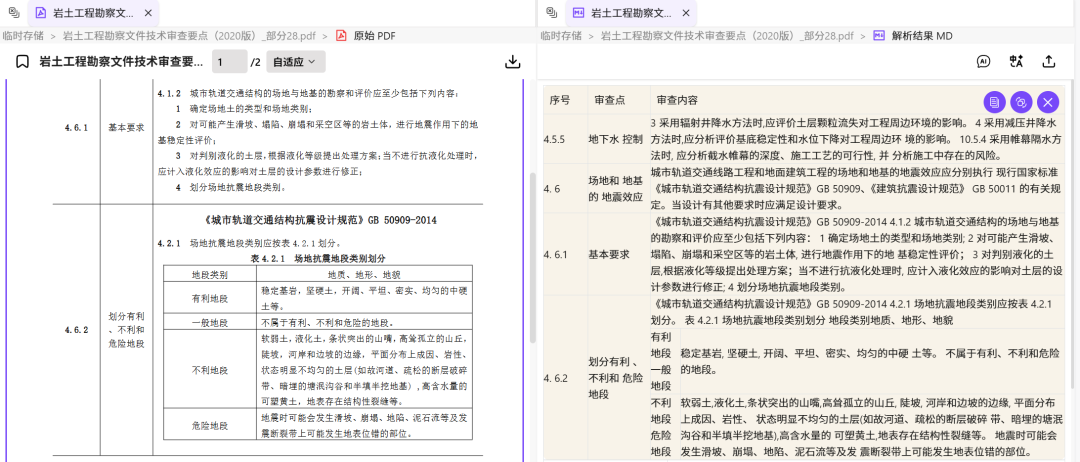
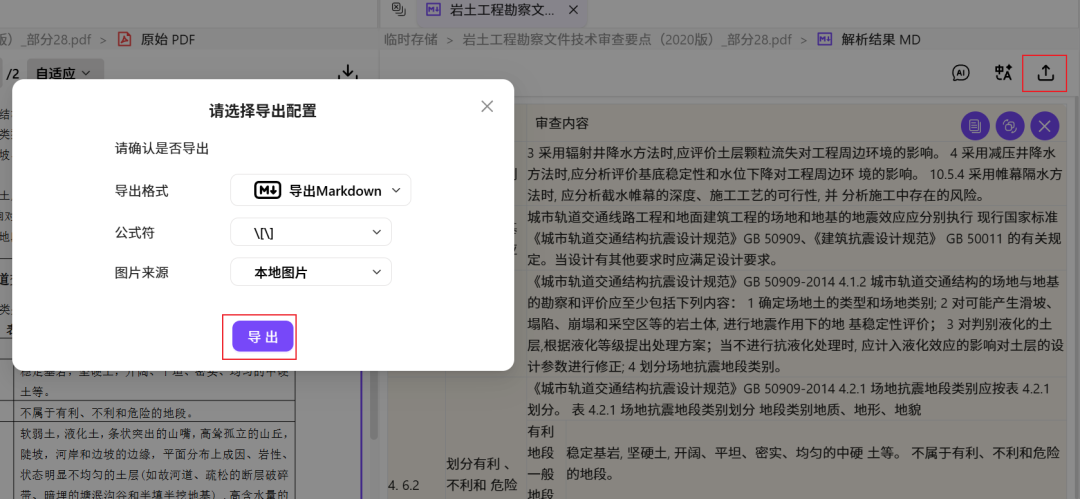
解析完成后,导出为 md 格式。
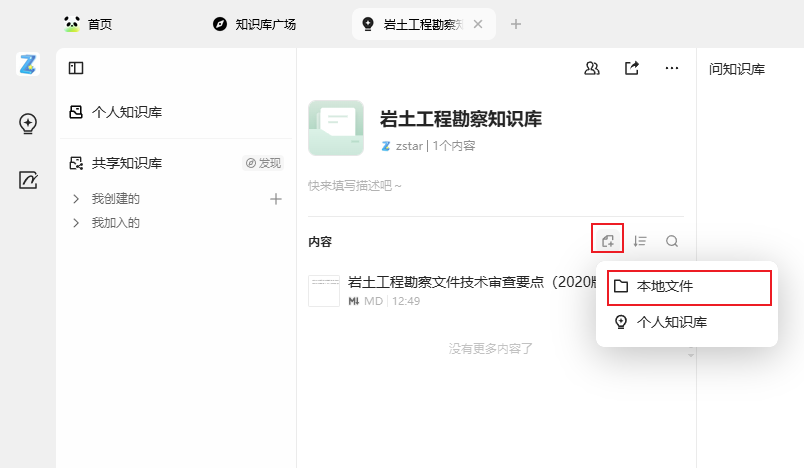
在 ima 中,创建新知识库,并上传文件。
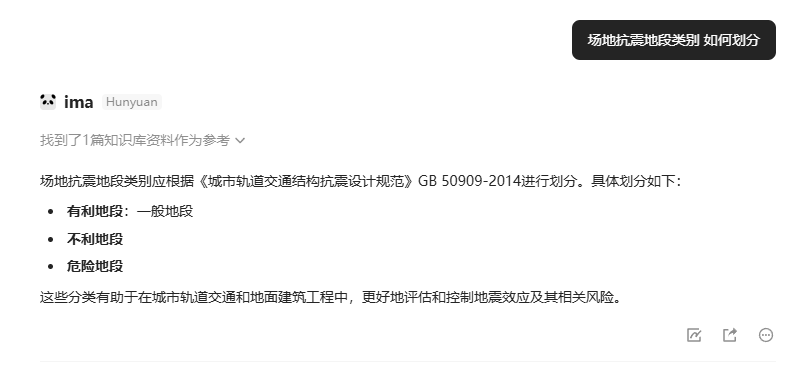
创建完文件后,就可以直接基于构建的知识库进行问答。

如果直接上传 PDF 文件,未通过 Doc2X 进行解析,模型将无法准确回答,说明经 Doc2X 解析后的复杂文件能有效提升模型的回答质量。
借助 API 接口实现文档解析
如果文件有很多,可以利用 Doc2X 的 API 实现解析,进一步简化操作。
Doc2X 开放平台:https://open.noedgeai.com
首先登陆 Doc2X 开放平台,注册并新建 APIKEY。
上传并解析文件
上传并解析文件的流程图如下:
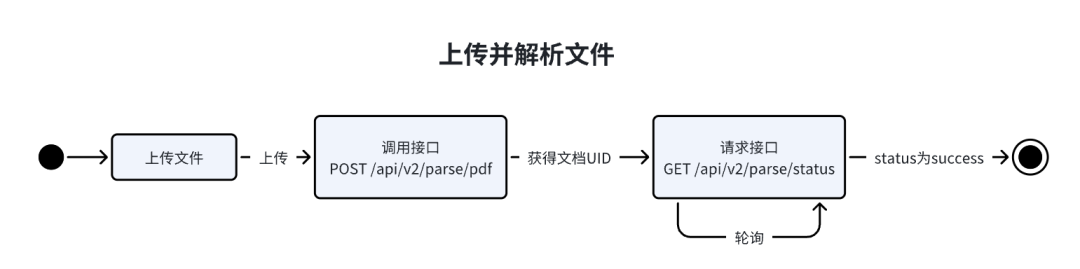
首先通过
/api/v2/parse/pdf接口上传文件。python示例代码如下:
之后通过
/api/v2/parse/status接口查看文件状态。python示例代码如下:
导出解析完成的文件
导出解析完成的文件,流程图如下:
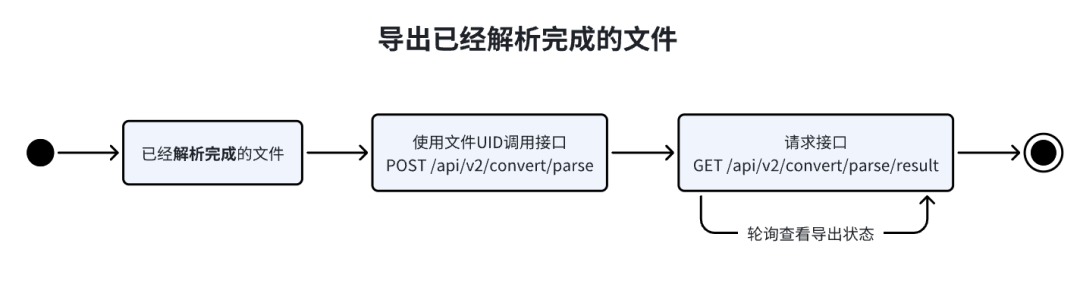
首先通过
/api/v2/convert/parse接口请求导出文件。python示例代码如下:
之后通过
/api/v2/convert/parse/result接口查看文件状态。python示例代码如下:
如果导出成功,可在
response.text获取到文件下载链接,可进一步将其下载为压缩包形式:总结
Doc2X 提供了文档解析与翻译转换的AI全方位解决方案,除了优秀的文档解析性能之外,还能接入大模型实现文档翻译,搭配极具性价比的定价,使其在此赛道中具备独特优势。