type
status
date
slug
summary
tags
category
icon
password
你是否曾被PDF文档中的文字、表格、公式提取搞得焦头烂额?传统的OCR工具往往难以应对复杂版面,多模态大模型又过于“笨重”?现在,一个全新的解决方案来了!
今天,我们隆重介绍MonkeyOCR——一个轻量级、高性能的多模态大模型,专为PDF解析和OCR识别而生。它不仅大幅提升了识别准确率,更在效率上实现了飞跃,让你的文档处理体验焕然一新!
MonkeyOCR研究方向:
- 研究问题:MonkeyOCR要解决的问题是文档解析,即将各种文档格式中的非结构化、多模态内容(包括文本、表格、图像、公式等)转换为结构化、机器可读的信息。
- 研究难点:该问题的研究难点包括:文档布局的多样性、多层次的视觉层次结构、多种模态的无缝集成。系统不仅需要在细粒度级别检测和识别内容,还需要重建底层结构和语义关系。
- 相关工作:现有解决方案主要分为基于管道的方法和端到端的方法。基于管道的方法(如MinerU和Marker)将文档解析工作流分解为一系列专门的子任务,但存在错误累积的问题。端到端的方法(如Qwen2.5-VL)通过统一的神经网络直接生成结构化表示,但在处理高分辨率、信息密集的文档时面临计算挑战。
首先我们来看一下官方给出的评测报告:
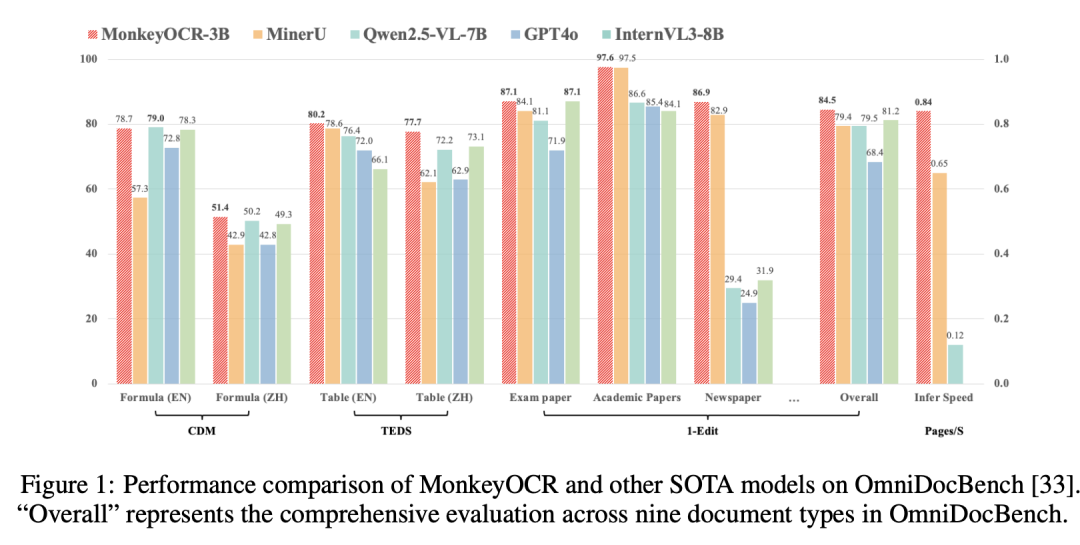
- 与基于流水线的方法MinerU相比,MonkeyOCR在九种类型的中英文文档上平均提高了5.1%,其中公式提高了15.0%,表格提高了8.6%。
- 与端到端模型相比,MonkeyOCR的 3B 参数模型在英文文档上取得了最佳平均性能,优于 Gemini 2.5 Pro 和 Qwen2.5 VL-72B 等模型。
- 对于多页文档解析,MonkeyOCR达到了每秒 0.84 页的处理速度,超过了 MinerU(0.65)和 Qwen2.5 VL-7B(0.12)。
整体效果上看确实达到了这些。
为什么说MonkeyOCR是“PDF解析的火眼金睛”?
传统的文档解析常常依赖于复杂的流水线式工具,或是庞大的端到端大模型。这些方法各有弊端:流水线容易出现误差累积,而大型模型则效率低下。MonkeyOCR的出现,打破了这一僵局,它采用了创新的结构-识别-关系(SRR)三元组范式,将文档解析抽象为三个核心问题:
- “它在哪里?” (结构):精准的版面分析,识别文档中的文本块、表格、公式、图片等各个语义区域。
- “它是什么?” (识别):高效的内容识别,无论是印刷文字还是手写笔记,甚至是复杂的数学公式和表格,都能准确提取。
- “它是如何组织的?” (关系):将边界框输入到一个专用的块级阅读顺序模型中,预测一个序列,将识别内容重新组装为最终的结构化输出,确保输出的结构化信息完整且符合阅读逻辑。
这种精妙的设计,让MonkeyOCR在准确性和效率之间找到了完美的平衡点。
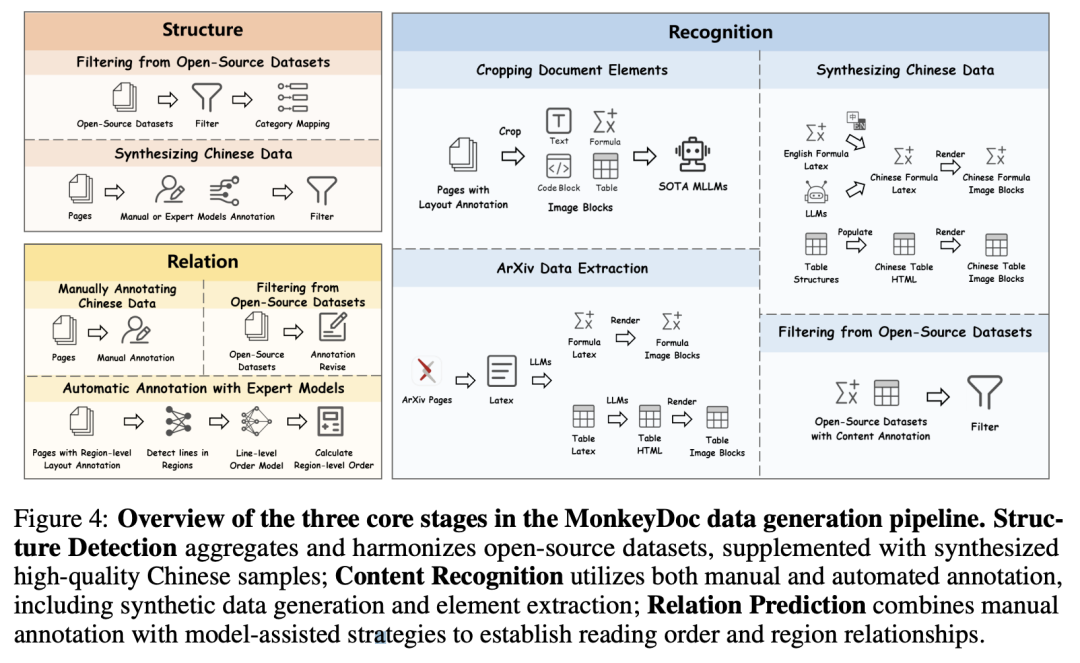
为了验证MonkeyOCR的有效性,研究人员在OmniDocBench基准上进行了广泛的比较实验。OmniDocBench包含981个PDF页面,涵盖9种文档类型、4种布局样式和3种语言类别。实验设计包括:
- 数据收集:使用公开可用的结构检测数据集(如M6Doc、DocLayNet、D4LA和CDLA)并进行过滤和协调,补充高质量的中文数据。
- 样本选择: 通过程序合成和手动标注生成额外的中文数据,确保数据多样性和高质量。
- 参数配置:使用AdamW优化器,学习率为2e-5,余弦学习率调度,批量大小为64。3B模型在32个A800 GPU上训练了53小时。

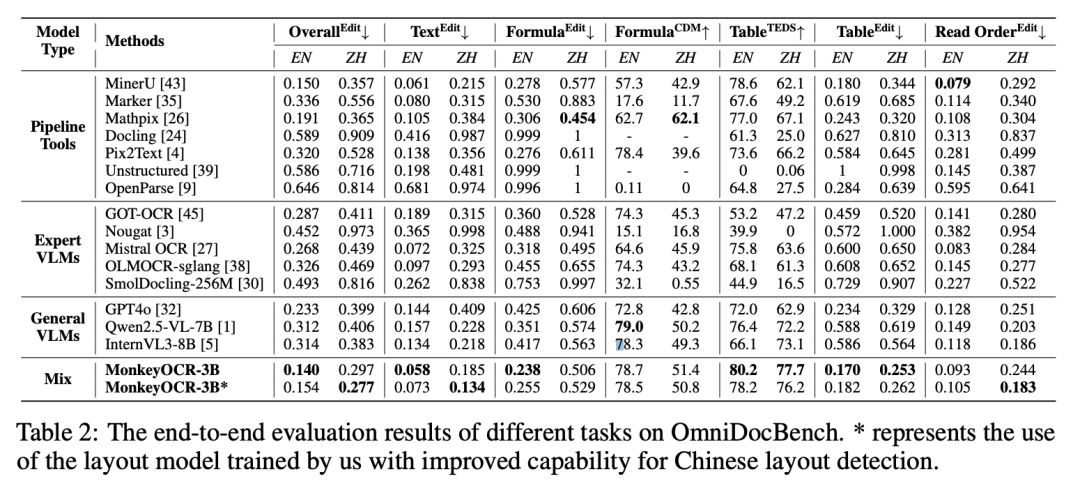
MonkeyOCR的硬核实力,数据来说话!
可别小看MonkeyOCR的“轻量级”,它的表现足以让众多“巨无霸”模型汗颜:
- 小模型,大能量! 仅仅30亿参数的MonkeyOCR,在英语文档解析任务上,超越了包括Qwen2.5-VL (72B) 甚至Gemini 2.5 Pro在内的许多更大、更顶级的模型,达到了行业领先水平!
- 复杂内容,轻松搞定! 对于PDF中最让人头疼的公式识别,准确率提升高达15.0%;表格识别也提升了8.6%。无论是学术论文、财报还是合同,MonkeyOCR都能精准还原。
- 中文支持,表现卓越! MonkeyOCR同样针对中文文档进行了优化,在中文文档解析任务上,即使是与顶级模型相比,也展现出极具竞争力的性能。
- 速度飞快,效率倍增! 处理多页文档时,MonkeyOCR的速度比同类系统快出数倍。单页文档也能达到极具竞争力的处理速度。这意味着你再也不用苦等文档解析结果了!
- 部署友好,人人可用! 令人惊喜的是,这款强大的30亿参数模型仅需一块NVIDIA 3090 GPU即可高效部署推理,让更多用户能够轻松体验到前沿的AI技术。
训练与未来:强大的数据支撑
为了打造如此强大的模型,MonkeyOCR团队构建了迄今为止最全面的文档解析数据集——MonkeyDoc。这个数据集包含390万个实例,涵盖了中英文在内的十多种文档类型,为MonkeyOCR的卓越表现奠定了坚实基础。
MonkeyOCR硬核测试示例!
这里我贴出部分复杂表格的识别,这些表格我在mineru、qwen2.5-vl 72B等等各类解析工具中从未100%识别。大圣居然识别对了!


原图
识别结果
可以看到表格还原度基本100%,并且表格内公式、下标都可以识别,目前可以称之为最强的。
MonkeyOCR的发布,无疑为文档处理领域带来了革命性的突破。它不仅提升了我们从PDF中获取信息的效率和准确性,更预示着未来AI在文档理解方面将更加智能、轻便。
想了解更多技术细节?或是亲自体验MonkeyOCR的强大功能?点击下方链接,访问项目GitHub仓库,探索更多!如果喜欢文档解析模型的可以关注一下这个公众号,您的点赞、转发、收藏是我更新的动力。我们下篇论文再见。
GitHub项目链接:https://github.com/Yuliang-Liu/MonkeyOCR?tab=readme-ov-file
在线体验链接:http://vlrlabmonkey.xyz:7685/