type
status
date
slug
summary
tags
category
icon
password
更新内容概述
前天晚上(2025.06.13),MinerU发布了v2.0.0版本,更新内容简单概括如下:
- 调用格式优化
之前调用 MinerU 安装的包名为
magic-pdf(MinerU仓库旧名),现在统一为 mineru,解决了命名一致性的问题。
- 部署方式优化 之前调用时,需要先手动下载模型,并生成 json 配置文件,现在模型无需手动下载,而会在首次调用时自动下载,并且具体配置信息可通过参数指定,无需再通过json配置文件。
- 文件结构优化 除代码结构优化之外,下载的模型目录和输出的结果目录会更加清晰。
- 方向垂直化 移除了内置的 LibreOffice 文档转换模块,解析文件将仅支持 pdf/jpg/png
- 全新的 VLM 解析方式 推出了仅0.9B参数量的 VLM 模型,单模型涵盖所有文档解析任务,精度优于传统 72B 级别的 VLM 模型。
总体而看,最重磅的更新是全新的 VLM 解析模式,实测表现也的确颠覆我对 VLM 的固有印象。
在本文中,以前的解析方式统称为基础解析方式,VLM解析方式则称为VLM解析方式。
MinerU 仓库地址:https://github.com/opendatalab/MinerU
MinerU 安装
下面使用 uv 来进行环境安装。
1. 安装uv
2. 安装python环境
MinerU v2.0 兼容的python版本为 3.10-3.14。
3. 创建uv环境
4. 激活uv环境
5. 安装MinerU
有以下两种安装版本:
直接安装核心版(无需 sglang 加速)
安装完整版(包含 sglang 加速,会多一些依赖)
MinerU 使用
MinerU 有三种使用方式:
1. 在线体验
MinerU 在 huggingface 部署传统的解析方式和新版的VLM解析方式。
基础解析方式体验地址:https://huggingface.co/spaces/opendatalab/mineru
VLM解析方式体验地址:https://huggingface.co/spaces/opendatalab/mineru2
实测下来,新的VLM解析方式很快,甚至比传统方式更快得到解析结果。
2. 命令行使用方式
安装好 MinerU 之后,可以通过命令行直接调用使用。
基本调用形式:
- -p:输入文件路径
- -o:输出文件路径
其它可选参数:
由于首次调用需要下载模型,因此建议国内使用时可添加
--source modelscope去从modelscope上下载模型,速度更快。调用示例:
需要注意的是,如果下载完 modelscope 模型,再下次调用时,如果不添加
--source modelscope,系统仍然会去下载huggingface模型。可以通过设置环境变量的方式永久添加该参数:
下载模型的默认保存路径为
C:\Users\%username%\.cache\modelscope\hub\models在新版本中,重新调整了模型下载路径,在该路径下,新增了
ReadingOrder和TabRec两个文件夹,用来预测阅读顺序和表格识别。模型没有变化,实质上就是将原有放置在外部的
models--hantian--layoutreader和models--slanet_plus两个模型放到整体的文件路径下统一管理。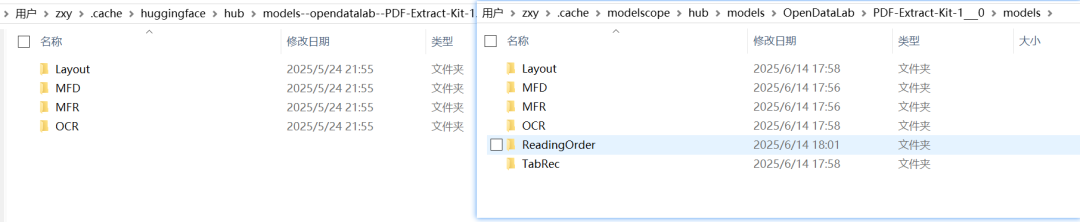
通过
-b 或 --backend参数,可指定使用基础解析方式或vlm解析方式:- pipeline:基础解析方式
- vlm-transformers:vlm解析方式
- vlm-sglang-engine:vlm加速解析方式
- vlm-sglang-client:vlm加速解析方式(连接sglang 服务调用)
后面会详细测试。
3. python调用方式
通过 python 调用运行,参数和命令行参数一致。
调用示例: https://github.com/opendatalab/MinerU/blob/master/demo/demo.py
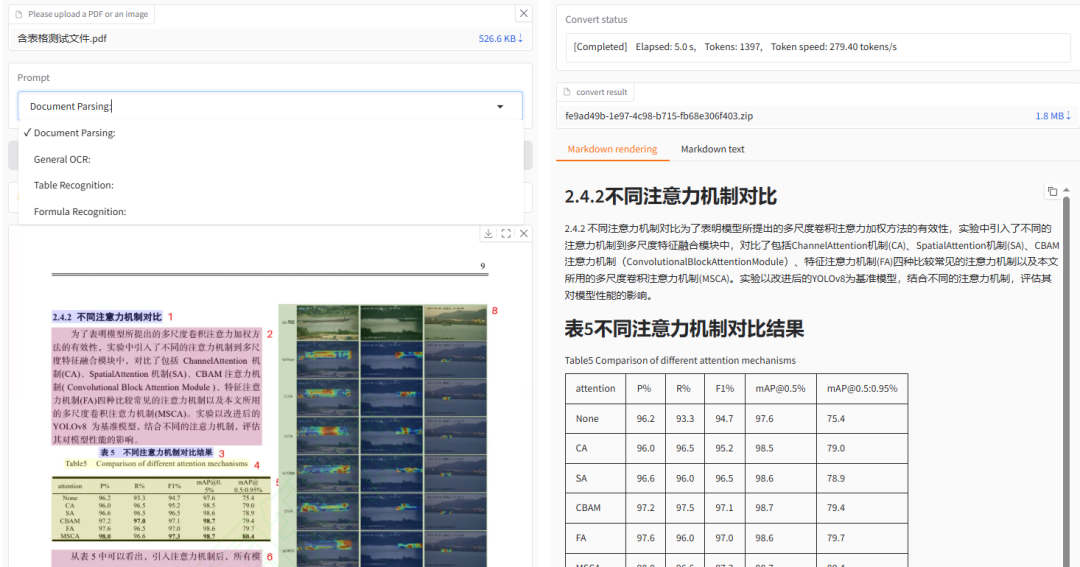
解析效果对比
下面进行具体的解析效果对比,选取了数学高考卷进行对比测试。

以下是 v1.13.12 和 v2.0.3 版本的基础解析算法对比,两者的区别不是很明显,因为模型没变化,对于其中的第10题,两者都没有将选项正确的进行排列。

下面是 VLM 方法的解析结果:

除了标题格式没有正常设置为一级标题之外,其它的内容基本正确,格式排列也比基础方法好很多。
下面是另一种表格嵌套的典型文件。

基础解析方法分块及解析结果:
基础解析方法会将整页文档当作一个表格处理,所有内容均在一个表格中,由于表格较为复杂,无法准确被预览器渲染。

VLM解析方法分块及解析结果:
VLM解析方法能有效提取大表格的内部信息,并进行标题、正文划分。

VLM解析效率测试
从上边的对比效果看,VLM 看上去效果更好。
那么,效果好的代价是什么?下面来进一步测试。
1. 参数说明
在前面的参数介绍中,有一个参数
-d/--device用来控制模型的推理设备,有以下的选择:- cpu/cuda/cuda:0/npu/mps
然而,该参数仅对基础方法有效,并不能对vlm解析生效。
实测发现,使用vlm解析,会自动选择设备,如果发现显存够用,则自动启动gpu加速;如果不够用,则会以cpu模式运行。
使用cpu模式运行vlm解析速度极慢,平均一页内容需要近二十分钟。因此,如果gpu显存不足,无需考虑使用cpu解析的方式。
2. vlm-transformers推理测试
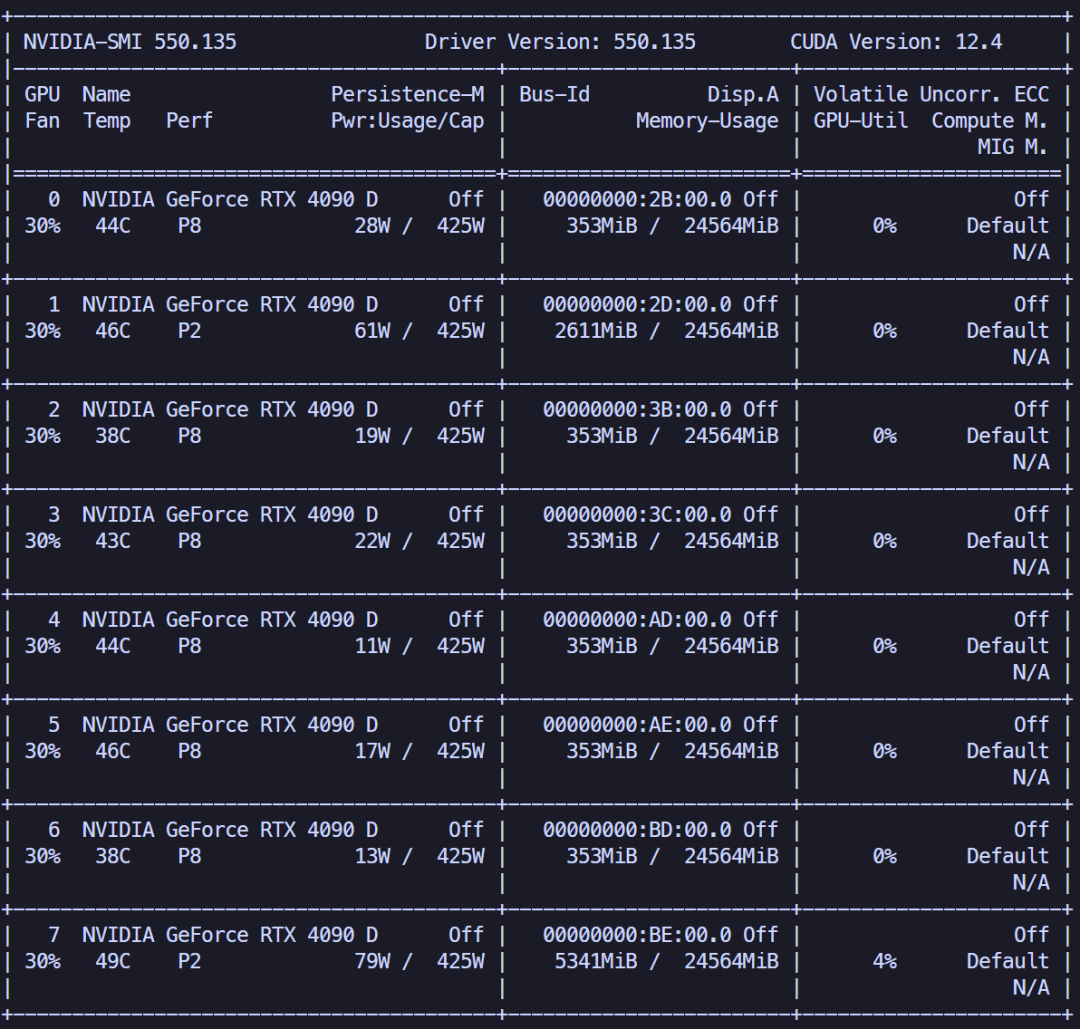
下面拿八卡4090D的服务器进行实验。
运行以下命令,直接用
vlm-transformers进行推理。观察显存占用情况,发现不加限制的情况下,它会自动用到所有的GPU资源,并会将主要的模型加载到其中的两张卡上。
既然无法通过内部进行显卡限制,可以通过外部指定
CUDA_VISIBLE_DEVICES来强行约束进程只看到限定的显卡。下面指定进程将所有显存放到第1张显卡(编号0)上。
实验发现,它占用了11.49GB的显存。
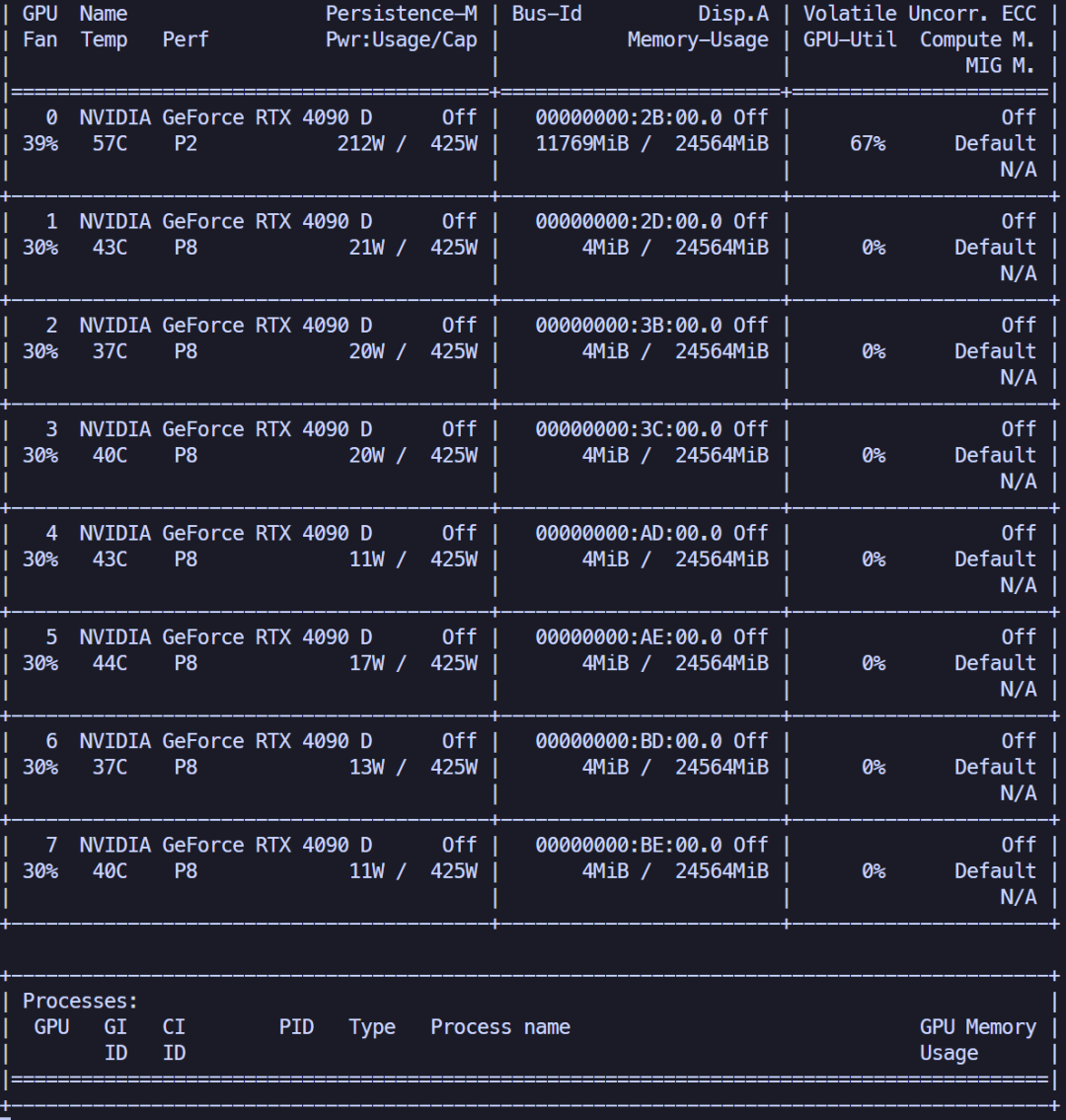
推理时间平均约20s/页。
换了另一个文件进行测试。
发现,它只占用了5.44GB的显存。
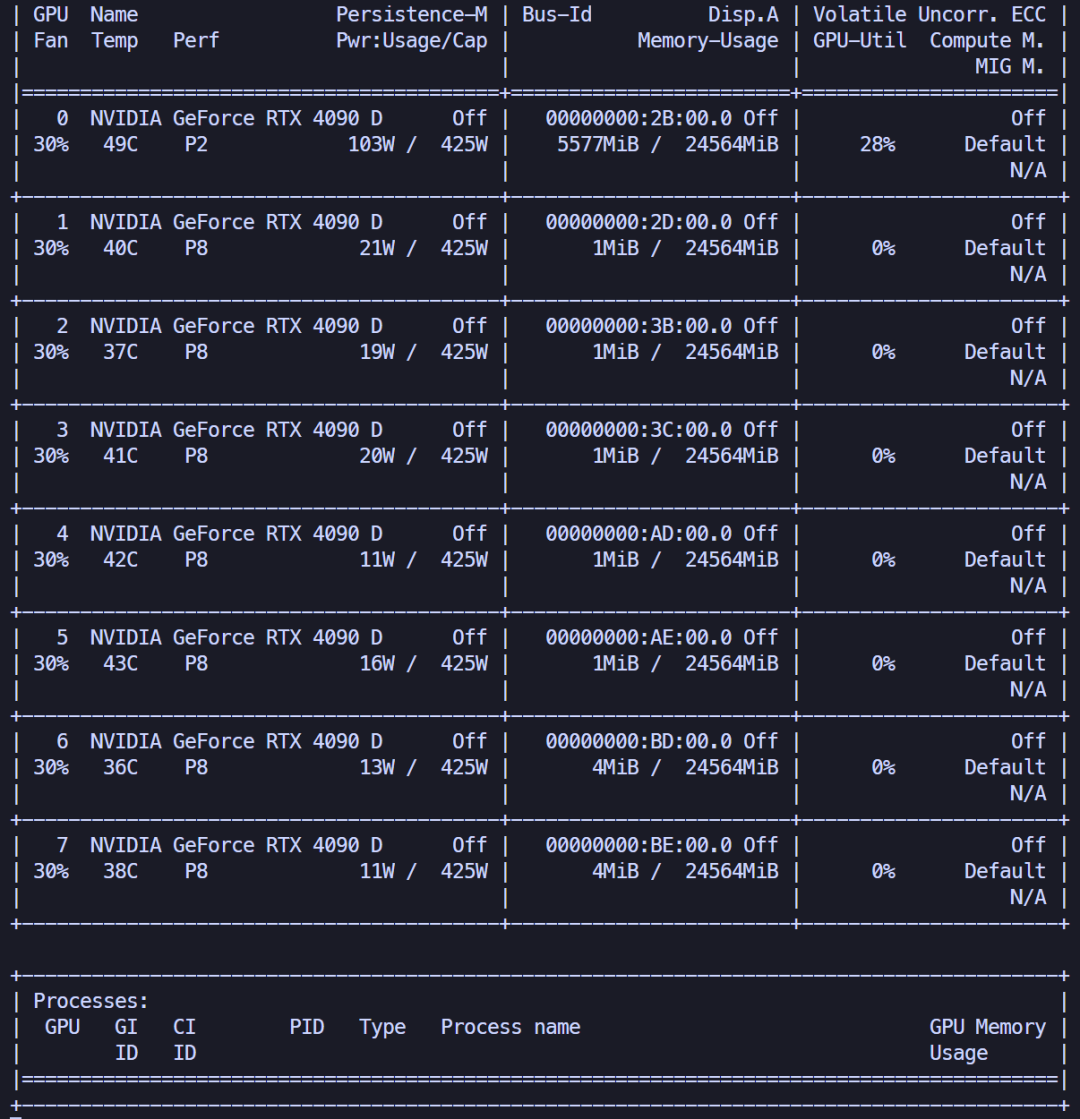
推理时间平均约20s/页。

此实验表明,不同的文件(pdf图像分辨率不一致)会导致不同的显存占用情况,但不影响推理速度。
对于vlm模型,不能简单地像llm模型那样,用模型本身地参数量去估计显存占用,因为文本本身占不了多少显存。
而vlm模型需要将图像编码成token,一旦图像分辨率很高,图像编码所带来的显存占用是不能轻易忽视的,甚至会远高于模型本身的显存占用。
3. sglang推理测试
20s/页还是不够快,官方说可以通过sglang框架进一步实现加速。
下面通过设定
vlm-sglang-engine参数来控制使用sglang推理。实测发现,对于第一个文件,显存占用会明显增加,达到了22.36GB。
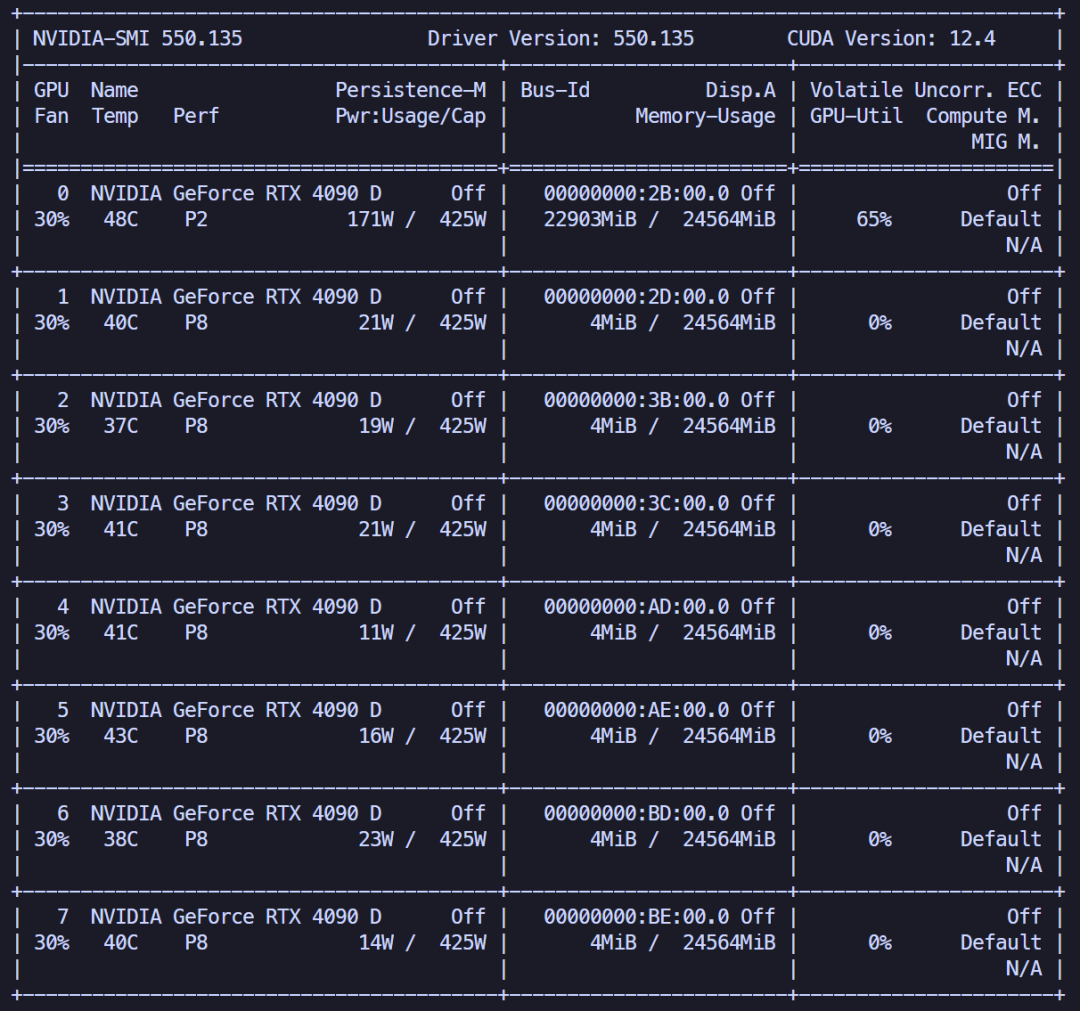
速度提升也非常明显,达到了5s/页。
对于第二个文件,显存占用依然没有明显变化,达到了23.12GB。
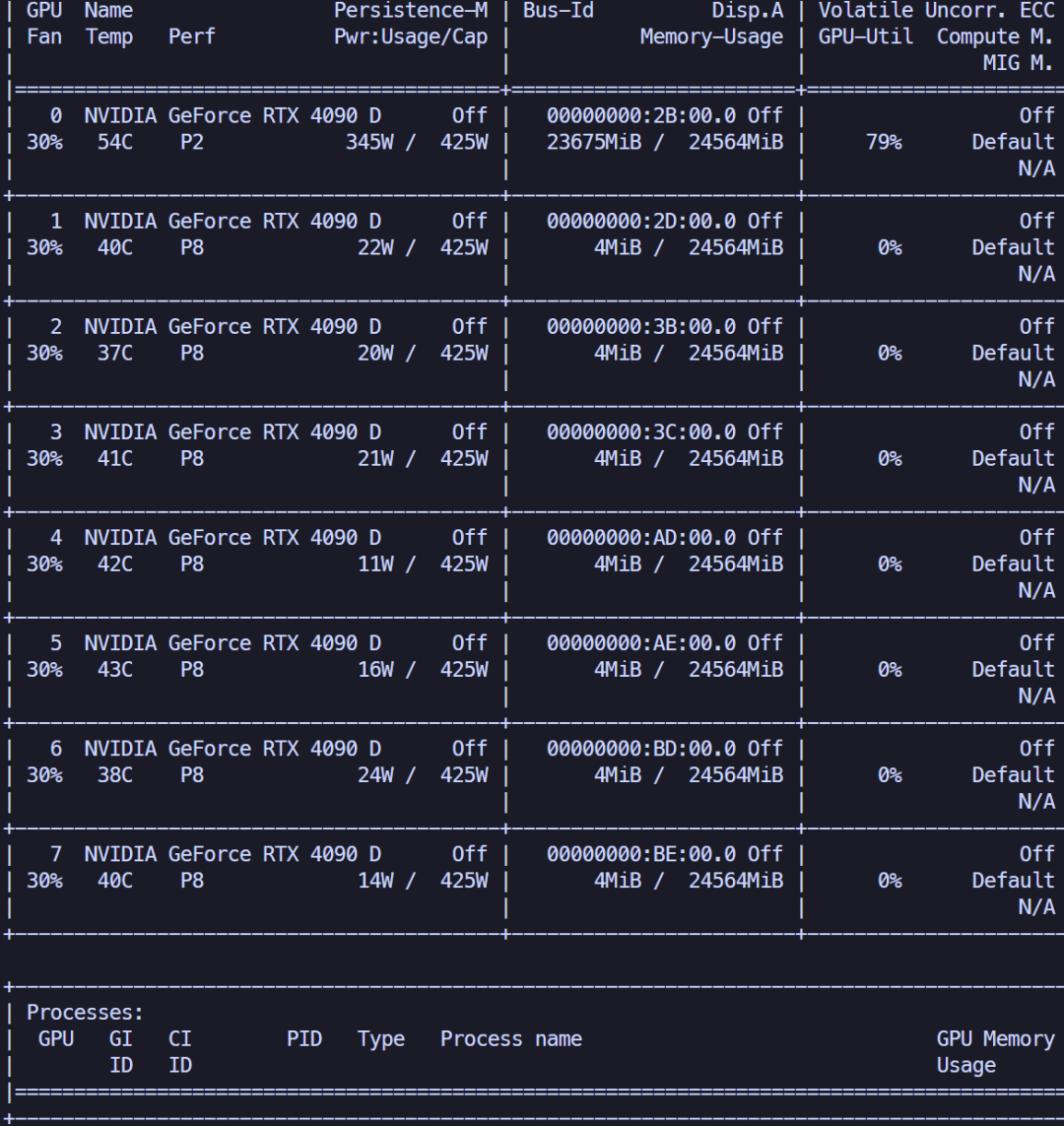
速度更为夸张,达到了1.6s/页。
我对sglang框架并不了解,估计是它内部采用了某些加速机制,可以通过更高的显存占用换取更快的时间,默认情况下,会尽可能最大利用剩余显存资源。
VLM 模型结构推断
做完实验,进一步思考,VLM采用了什么结构,让模型效果又小又好呢?
通过模型下载配套的
config.json,可以看到模型的具体结构信息。结构概括如下:
其实整体架构和之前文章分析过的
Qwen2.5-VL没有本质上的差别。可能作者团队还做了很多数据优化/训练策略改进,具体可以等他们发布技术报告。
报错解决记录
在用 sglang 推理时,遇到如下报错:
解决方式是安装cuda和安装gcc/g++(版本11)。
安装cuda:
安装gcc/g++:
设置gcc版本:
检查版本:
RagflowPlus同步问题
之前有群友问:MinerU 更新到新版本了,RagflowPlus考虑同步更新吗?
回答:不急,先看看,原因如下:
- 1.诚然,MinerU新版本VLM解析方案确实看上去效果更好。但是,其对显存管理仍存在提升空间。
- 2.一个产品的大版本更新,往往意味着会有各种bug问题,当前MinerU作者团队也是在加班修bug,两天时间连更3个小版本(截至目前最新到v2.0.3)。
- 3.RagflowPlus目前已到了稳定期,仓库中的issue基本都已解决关闭,产品目前也在项目中部署应用,对于大部分一般材料 MinerU 基础解析能力足够应对。
- 4.我对新技术始终秉持保守态度。在彻底搞清楚新东西的原理之前,不会贸然去做。
总结
之前写 Dolphin 的分析文章时,我对 VLM 进行文档解析的路线始终不抱希望,因为之前的规律表明:只有模型参数足够大,才能获得好效果,小参数模型一致难以企及大参数模型的性能。
MinerU 0.9B 的 VLM 模型让人眼前一亮,一个模型同时解决了布局分析、公式识别、文本OCR等各种任务,而且效果不错。本文中的实验结果表明,每块部分都由小模型去做,虽然能应对大多数场景,但对于部分复杂场景,它的瓶颈也暴露无疑,很难再通过数据训练去突破。
而 VLM 不一样,它的性能瓶颈看上去还没有达到,因此它有机会突破基础解析效果的天花板。后面有时间打算再从源码角度,分析它究竟是如何去做的,为什么采用通用的基础架构,能产生蚂蚁撼大象的效果。