type
status
date
slug
summary
tags
category
icon
password
在处理 PDF 文档时,很多 OCR 工具在遇到跨页表格、跨列段落、多语言混排时常常识别混乱、结构丢失、格式错乱……
最近一款由 ChatDOC 团队开源的工具 OCRFlux 正式上线,可以原生识别跨页元素、自动合并表格/段落、输出优质 Markdown 结构文档。

OCRFlux 是一个轻量级但功能强大的多模态工具包,显著提升了 PDF 到 Markdown 的转换效果,在复杂布局处理、复杂表格解析和跨页内容合并方面表现出色。
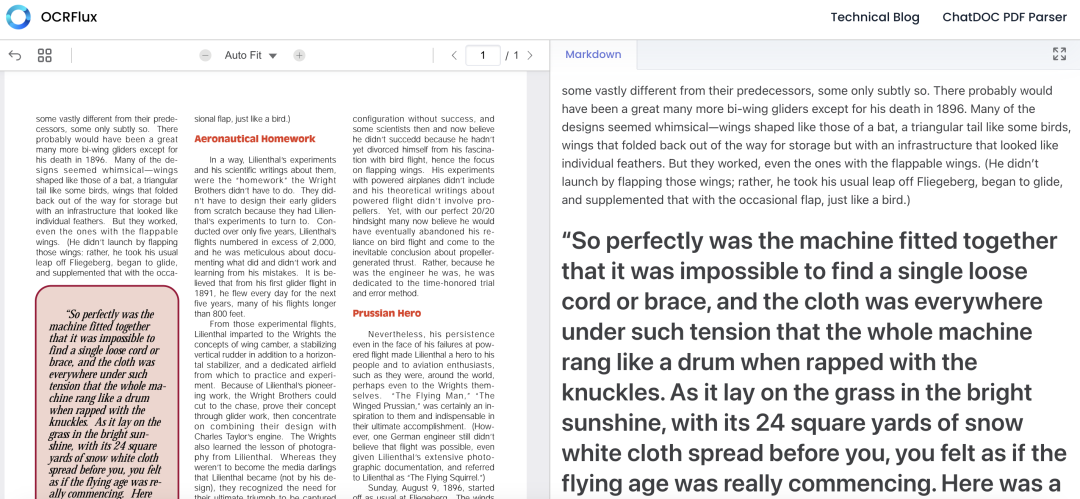
其3B参数模型,在GTX 3090 GPU上处理速度比7B参数的基线模型还要快上3倍。
在OCRFlux-bench-single基准测试的EDS指标,中英文场景下都超过了olmOCR-7B-0225-preview、Nanonets、MonkeyOCR。
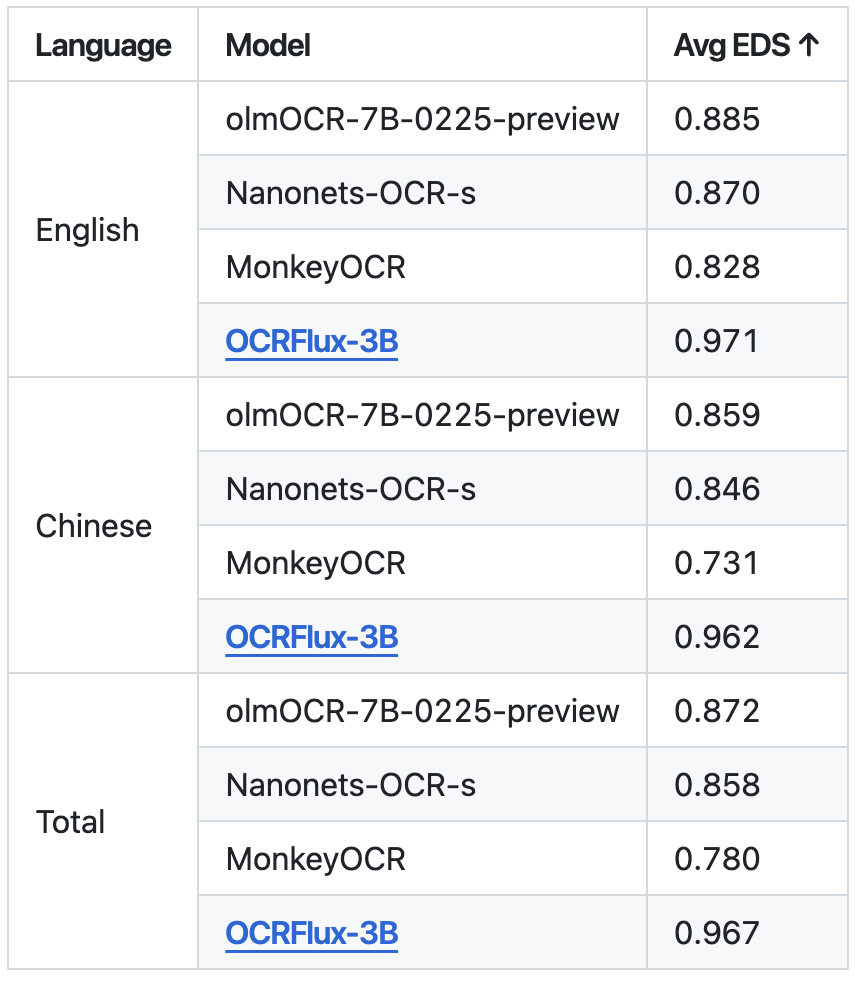
EDS:生成的Markdown与真实Markdown之间的编辑距离相似度。
准确率达到了98.3%,主要依赖其用原生结构建模方式,把复杂 PDF 文档准确转为 Markdown,特别适合结构复杂的资料型文件。
主要功能
- • 跨页元素合并:自动检测并合并跨页表格/段落,保持逻辑完整,准确率98.3%。
- • 多列布局识别:支持单列/多列复杂布局,按自然阅读顺序输出Markdown。
- • 中英双语支持:精准解析中英混排。
- • 轻量级高性能:仅 3B 参数,在 GTX 3090 上速度比 7B 模型快 3 倍。
- • 图表提取:提取图像、表格,生成带描述的Markdown嵌入。
技术亮点
- • 跨页元素跟踪机制:解决了传统 OCR 工具“分页即断”的问题,适合处理长表格/长段落
- • 结构化解析器:基于段落流、表格流、标题流等概念,对文档元素进行自然组织
- • 多模态预训练机制:融合视觉+布局+文本,提升对复杂文档结构的鲁棒性
- • 可嵌入 Markdown、HTML、LaTeX 等下游系统
快速使用
ChatDoc 团队在线上发布了一款在线Demo,可以直接进行 OCR 文档识别。但仅支持解析上传文档的前3页。
OCRFlux 在线体验:https://ocrflux.pdfparser.io
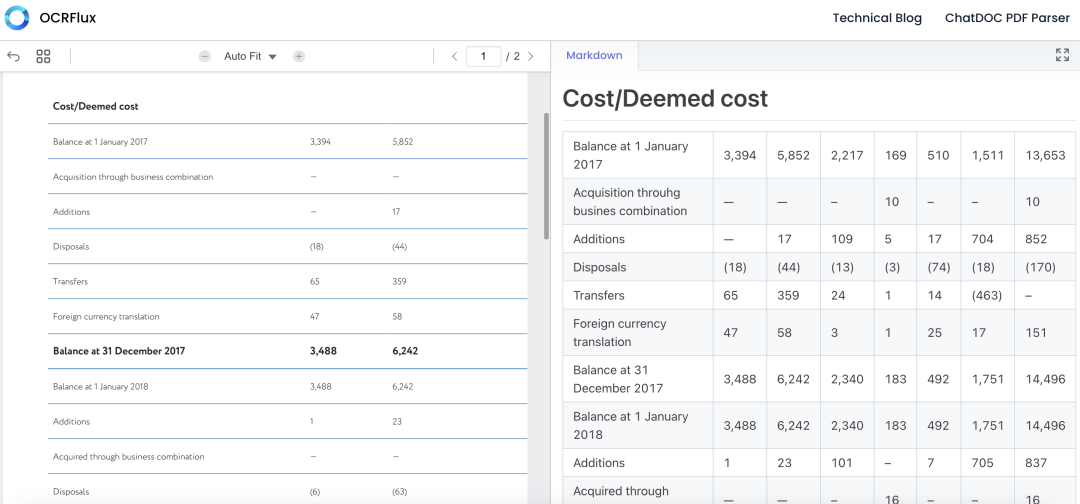
如果想要更完美的使用OCRFlux的功能,可以通过本地源码部署或Docker部署方式进行。
1、本地源码部署
创建Python虚拟环境,克隆项目,安装依赖
2、Docker快速部署
本地使用用法:
PDF转Markdown
图像转Markdown
批量转Markdown
可以设置
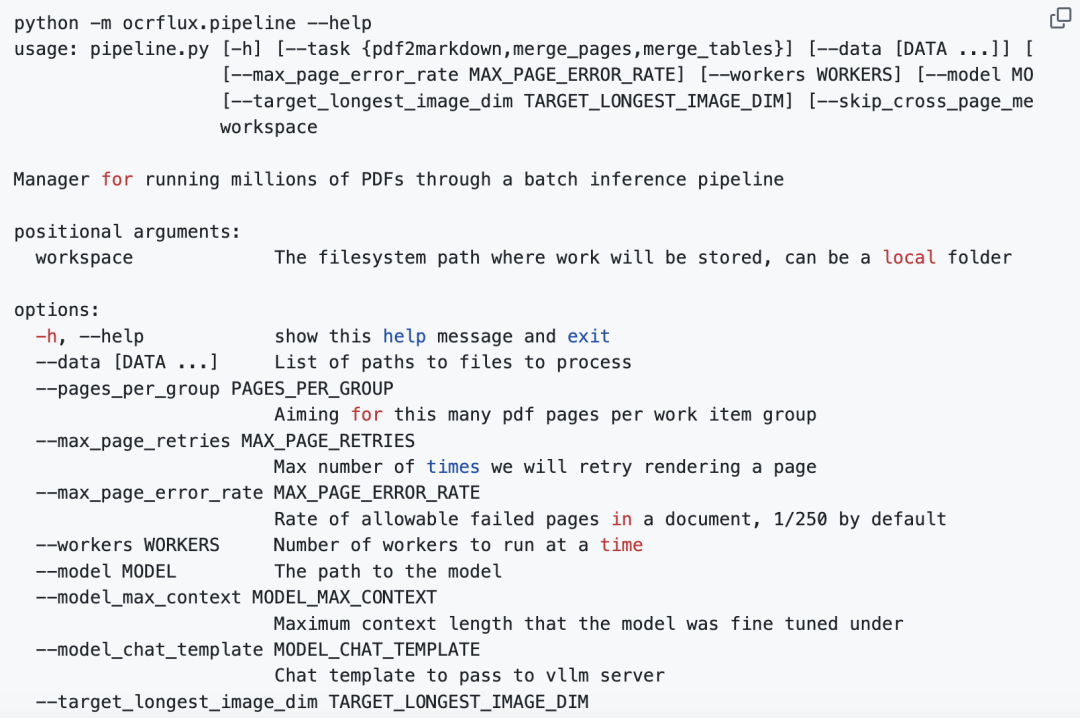
--skip_cross_page_merge 来跳过解析过程中的跨页合并,以加速处理,它将简单地连接每个页面的解析结果,生成文档的最终Markdown。完整的命令管道参数使用,参考项目文档上说明的进行。
写在最后
OCRFlux 是首个在所有开源项目中支持原生跨页表格/段落合并的OCR工具,并以3B参数高效模型,革新PDF转Markdown体验。
即使存在多栏布局、图表和插图,也能转换为具有自然阅读顺序的文本,支持复杂的表格和方程,可自动移除页眉和页脚。
是处理结构复杂文档时的 Markdown 工具首选,特别适合构建知识库、RAG 系统或 AI 语义提取场景!
GitHub 项目地址:https://github.com/chatdoc-com/OCRFlux