type
status
date
slug
summary
tags
category
icon
password
更新信息概述
昨天(2025-05-24),MinerU 进行了一轮小版本更新,当前版本更新到 v1.3.12。
MinerU项目地址:https://github.com/opendatalab/MinerU
此轮更新围绕
ppocrv5 模型展开,涵盖以下两点:- 将
ch_server模型更新为PP-OCRv5_rec_server,ch_lite模型更新为PP-OCRv5_rec_mobile。
- 增加手写文档的支持:通过优化layout对手写文本区域的识别,现已支持手写文档的解析
可通过lang参数
lang='ch_server'自行选择相应的模型:ch:PP-OCRv4_rec_server_doc(默认)(中英日繁混合/1.5w字典)
ch_server:PP-OCRv5_rec_server(中英日繁混合+手写场景/1.8w字典)
ch_lite:PP-OCRv5_rec_mobile(中英日繁混合+手写场景/1.8w字典)
ch_server_v4:PP-OCRv4_rec_server(中英混合/6k字典)
ch_lite_v4:PP-OCRv4_rec_mobile(中英混合/6k字典)
注:ppocrv5(server)对手写文档效果有一定提升,但在其余类别文档的精度略差于v4_server_doc,因此默认的ch模型保持不变。
更新模型下载
由于此次更新替换了部分模型,需要重新下载模型,有以下两种下载方式:
1. 从huggingface上下载
运行下载脚本:
2. 从modelscope上下载
运行下载脚本:
如果是 Linux 系统,也可以不手动创建py文件,快速执行以下命令,达成相同效果:
Torch-Infer 项目同步
之前我单独把 MinerU 的文本OCR部分单独提取出来,专门建立了一个仓库,方便在其它项目中集成
此次也进行同步更新。
MinerU中的模型配置文件位于:
模型理论效果最好的组合是
ch_server:因此,把 det 和 rec 模型都进行同步更新。
v5 字典文件文本分类类别数从 6623(v4) 扩展到 18384。
从字典文件中,发现竟然还包括各种表情符号,也就是说,它们也能被ocr识别出来。
实际测试了一下,大部分情况 v5 和 v4 效果差不多,少部分情况,如繁体字,v5 会支持得更好。
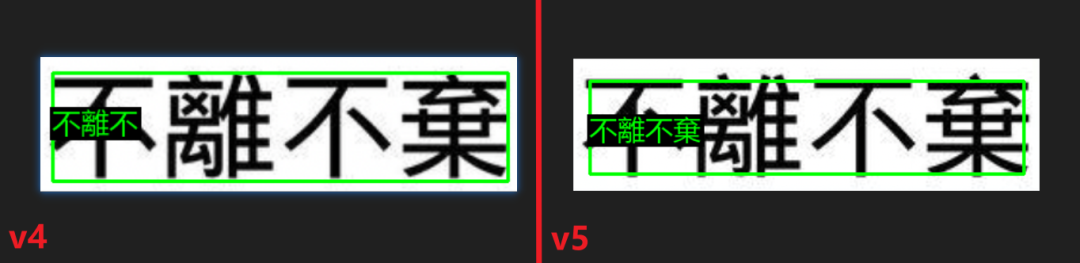
v4/v5识别效果对比