type
status
date
slug
summary
tags
category
icon
password
本文全文1378个字,阅读需要3分钟
“ 在AI大模型狂飙的2025年,一份PDF文档可能藏着科研突破的关键数据,也可能承载着企业决策的核心信息。但面对格式混乱的PDF、图文交错的网页,你是否还在手动复制粘贴?
GitHub上爆火的国产开源项目MinerU,正在用一行代码解决这个世纪难题。”

这个工具到底能做什么?

MinerU是上海人工智能实验室的出品,它就像一位“文档翻译官”,能将PDF、网页、电子书等复杂格式一键转换为工整的Markdown或JSON。
有了它,科研党需要将200页论文中的公式批量转成LaTeX格式,原本需要3天的手动操作,MinerU只需3分钟;金融分析师处理财报时,表格自动转HTML代码,数据直接导入Excel分析;程序员抓取技术文档时,智能过滤广告和页脚,保留核心代码块。

它具备的核心能力是:
- 精准解析:智能识别文档结构(标题/段落/列表),跨模态提取图片、表格、公式,连扫描件乱码都能自动OCR修复
- 格式还原:删除页眉页脚等干扰元素,按人类阅读顺序排版,多栏文档也能正确排序
- 全场景适配:支持Windows/Mac/Linux系统,CPU/GPU/NPU多硬件加速,84种语言文档通



目前支持各种终端:

同时也支持API的方式接入,另外就和之前所说,这个项目是开源的,大家可以在这个基础上进行维护和添加。目前已经GitHub上累计了3万颗星。
在大模型的时代,MinerU的功能可能会更加珍贵,因为很多数据源都包含了很多格式和广告,用这个工具做一次数据清洗再放入大模型知识库会取得更好的效果。
使用方式
由于支持PC的客户端,MinerU 的部署方式非常简单,直接去官网(https://mineru.net/)下载对应的版本就可以进行使用了!

下载之后,我来做个测试:
- 首先,我放入这篇文章
https://www.sohu.com/a/887209656_123753?scm=10001.1586_13-100000-0_922.0-0.0.a2_5X162X1906&spm=smpc.channel_258.Block_1741338093162_272_fVRWaA_1_focus.1.1745252053248eS4mYdq_1090
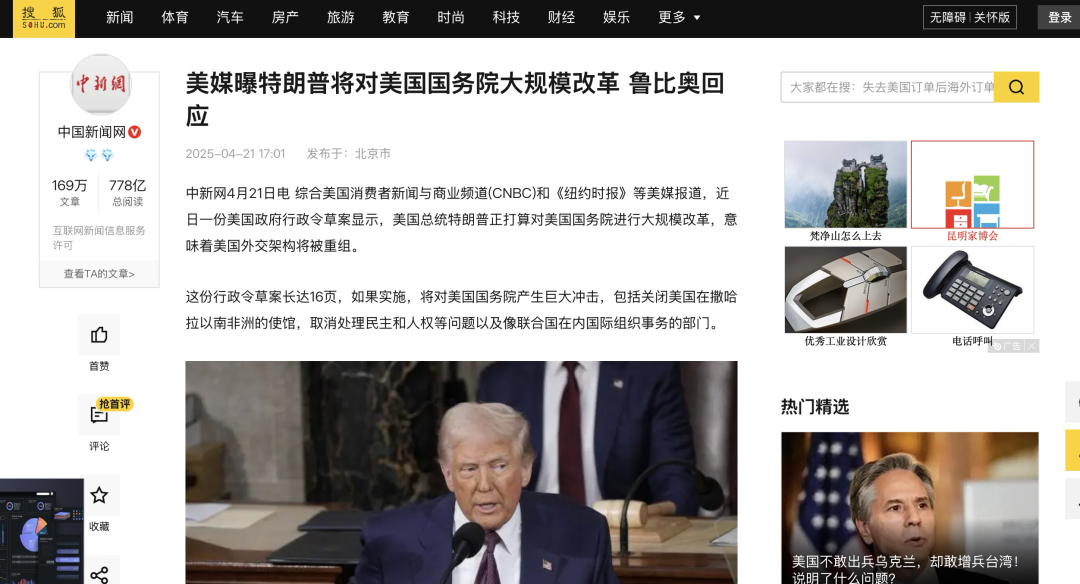
可以看到这文章页面很乱,各种广告和侧边栏,正常的提取方式很难提取准确,费时费力。
- 然后我把这个县把这个页面保存为pdf,然后放入本地的MinerU客户端:

可以看到他会把一些广告主动提取出来,然后你可以直接删除,这样比直接复制方便的多了,又避免了格式问题。
另外我还做了一个以太坊2024年年度报告的pdf的切分,可以看到图和文字的切分效果还是不错的。
