type
status
date
slug
summary
tags
category
icon
password
概述
MinerU更新频率也相当频繁,在短短一个月内,更新了10个小版本。
本文结合最新版本
v1.3.10,深入拆解下它进行文档解析时的内部操作细节。MinerU仓库地址:https://github.com/opendatalab/MinerU
环境准备
在之前的文章中,已经安装了
magic-pdf(MinerU的解析包名),先通过以下的命令进行升级。如果是第一次安装,不需要加
--upgrade参数:解析步骤拆解
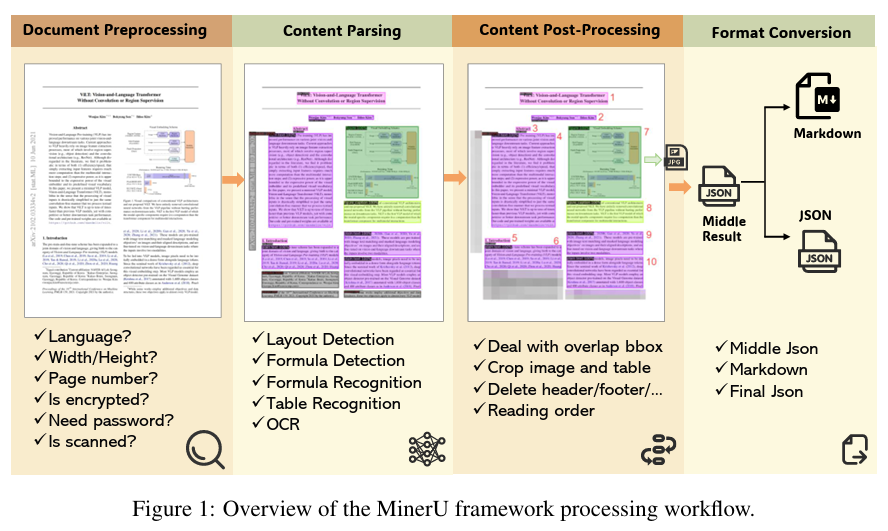
图源:MinerU: An Open-Source Solution for Precise Document Content Extraction
下面根据官方提供的运行示例,一步步拆解具体的流程。
内容长度超出 block limit:2000. 请手动补充该部分内容!
1. 数据读取
调用:
magic_pdf\data\data_reader_writer\filebase.py中FileBasedDataReader的read_at方法可设定
offset和limit两个参数:- offset:控制读取时的偏移量,比如从第n个字符后开始读取
- limit:控制读取的长度,比如读取n个字符
默认读取文件所有内容,以二进制形式读取,直接加载进内存。
如果文件特别大,可以考虑用这两个参数做分批读取。
2. 文件类型分类
对于PDF文件,进一步判断是图片型PDF(扫描件)还是文本型PDF。
具体判断逻辑在
magic_pdf\filter\pdf_classify_by_type.py的classify函数:这里进行了多方面的判断,具体方式如下:
classify_by_area如果 PDF 里大部分页面(超过一半)的主要内容都是一张大图片(图片面积占了页面面积的一半以上),那就认为这个 PDF 是扫描件,需要 OCR 处理,否则认为这个 PDF 是文本型的(返回 True)。(在判断前,它会先尝试去掉水印图片,并把可能被切成小块的图片拼起来。)
- classify_by_text_len随机抽取一部分页面,只要其中任何一页的文字数量超过 100 个字符,就认为这个 PDF 是文本型的(返回 True)。
- classify_by_avg_words计算 PDF 所有页面的平均字符数,如果平均每页字符数超过 100,就认为这个 PDF 是文本型的(返回 True)。
classify_by_img_num检查 PDF 是否属于一种特殊扫描件,其特点是:去除重复图片后,几乎每页都没有有效图片了,但原始图片数量在大部分页面上都非常多且数量一致。如果不是这种情况,就认为它是文本型 PDF(返回 True)。
classify_by_img_narrow_strips检查 PDF 中是否有一半以上的页面,其绝大部分图片(至少 5 张且占该页图片总数的 80% 以上)都是非常细长的(即宽度占页面宽度的 90% 以上且至少是高度的 4 倍,或者高度占页面高度的 90% 以上且至少是宽度的 4 倍)。如果这种情况的页面比例低于 50%,则认为 PDF 在这个维度上倾向于是文本型的(返回 True)
- invalid_chars在扫描 PDF 文件内容时,是否检测到了无效或无法正常显示的字符,如果没有,判定为文本型(返回 True)。
最后,综合这6个条件,如果这6个条件都为True,即判定文件是文本型的PDF,有任意条件不通过,则判定文件为图片型PDF。
3. 设备选择
在正式处理前,需要先指定运行设备。
首先需要读取配置文件,相关代码在
MinerU\magic_pdf\libs\config_reader.py该代码表明,它会根据系统环境变量
MINERU_TOOLS_CONFIG_JSON去查找json的配置文件。如果未设置此环境变量,默认会到用户家目录下,寻找
magic-pdf.json这个文件。该文件中,
device-mode设定了模型运行的设备,有cpu、cuda、npu三种模式进行选择(如果填入值非这三类,视作cpu)。如果选择了
cuda或npu,会自动计算显存容量,并自适应调节batch_ratio,具体调节规则如下:对于CPU设备,
batch_ratio默认设为1。顺带一提,在配置文件中,无法显性指定多卡同时解析,如有多卡解析的需求,可参考仓库中基于 LitServe 的多 GPU 并行处理方案。
文件地址: https://github.com/opendatalab/MinerU/tree/master/projects/multi_gpu
4. 解析处理
具体的处理流程在
magic_pdf\model\batch_analyze.py。图片型PDF会比文本型PDF多一个OCR处理的步骤,其它步骤一致。
1.布局分析
布局分析提供了两套模型可供选择:
layoutlmv3和doclayout_yolo,默认采用后者。doclayout_yolo也是MinerU所在组织OpenDataLab的研究成果。仓库地址:https://github.com/opendatalab/DocLayout-YOLO
该算法是基于
YOLO-v10对文件布局标记的数据集D4LA和DocSynth300K进行训练,从而检测出不同的布局信息。数据集包含的文档布局示例如下:

DocSynth300K数据集类别可视化
2.公式处理
公式处理包含两个阶段:公式检测(MFD) 和 公式识别(MFR) 。
公式检测是指检测出公式所在位置,采用
yolo_v8_mfd算法,未找到该算法的详细介绍,根据揣测是采用yolov8算法,在公式块标记的相关数据集上进行训练得到。公式识别是指在得到公式区域的基础上,识别其中的具体内容,将其中的数学表达式图像转换为 LaTeX 语言,具体算法采用
unimernet算法。该算法也是OpenDataLab的自研算法。
仓库地址:https://github.com/opendatalab/UniMERNet
考虑到并不是所有的PDF文件中都有公式,因此,可以在配置文件中,将其关闭。默认的
"enable"设置为开启状态,如需关闭公式处理,设为false。3.OCR处理
OCR是指将图像区域内容识别成文本,和公式处理类似,同样包含区域检测和区域识别两个阶段。
这两个阶段均是使用百度的PaddleOCR,该算法原生使用的PaddlePaddle框架,这里使用了pytorch的实现版本。
在这个文件
magic_pdf\model\sub_modules\ocr\paddleocr2pytorch\pytorch_paddle.py中,有一个测试样例。对于不同的语言进行OCR,需要使用不同的模型,在
magic_pdf\model\sub_modules\ocr\paddleocr2pytorch\pytorchocr\utils\resources\models_config.yml这个配置文件,规定了不同语言所对应的采取的不同模型。对于中文文本,检测模型使用
ch_PP-OCRv3_det_infer,识别模型采用ch_PP-OCRv4_rec_infer。在下载模型时,会将所有常见语言(中文、英文、日文、拉丁文等语言)的模型一次性下载下来,每个模型体积不大,基本在10-20MB左右。
4.表格识别
表格识别包含两个部分:表格文本识别和表格结构识别。
表格文本识别默认采用
rapid_table这个依赖库,底层同样使用的是PaddleOCR,用来识别表格中的文本内容。表格结构识别默认采用
slanet_plus算法,用来识别表格结构。该部分代码来自RapidTable这个仓库。
仓库地址:https://github.com/RapidAI/RapidTable
表格识别同样可以在配置文件中自由选择关闭,和公式处理一样,通过
enable参数来控制开启和关闭。5. 结果输出
最后可输出结果包括:
- model.pdf:布局分析的可视化结果
- file_layout.pdf:布局分析后,去除页眉页脚,标记真正内容的可视化结果
- spans.pdf:文本/图像/公式/表格区域检测的可视化结果
- middle.json:每一区域识别的中间结果
- content_list.json:分块内容识别结果,对每段落的小块区域进行合并
具体的相关接口参见
magic_pdf\operators\pipes.py其它文件处理
由于MinerU是针对PDF进行解析,因此本身的处理管道并不能处理其它格式的文件。
在
v1.0.1版本后,进一步支持图像(.jpg及.png)、Word(.doc及.docx)、以及PPT(.ppt及.pptx)三类文件的解析。1. MS-Office文件解析示例
对于 MS-Office 文件,需要通过 LibreOffice 将其转换成 PDF文件,再复用PDF的解析管道。(本地使用时,需要提前安装LibreOffice,并设置相应环境变量)
python示例脚本如下:
具体转换过程在
magic_pdf\data\read_api.py文件的read_local_office方法。考虑到Excel文件也属于
MS-Office文件,因此,拿excel文件试了一下,发现也能正常跑通,只是会将整张表格内容变成一个html的格式,没有自动将每行内容区分开。另外,拿这个脚本试了下
.txt和.md文件,发现也能正常使用,后面可以直接借此拓展RagflowPlus的文件支持形式。2. 图片文件解析示例
对于图片文件,无需转换成pdf,原本的管道可兼容,示例python脚本如下:
补充材料
查看源代码时,发现了
MinerU实际上复用了很多PDF-Extract-Kit的代码。MinerU更多的是工程上的整合,如需更细致地挖掘某个步骤,可参考同属opendatalab的PDF-Extract-Kit这个仓库。