type
status
date
slug
summary
tags
category
icon
password
一、MinerU让文档数据活起来
MinerU (https://mineru.net)是由上海人工智能实验室(上海AI实验室)大模型数据基座OpenDataLab团队开源的全新的智能数据提取工具。MinerU 能够快速识别复杂PDF版面元素,将文档转化为清晰、通顺、易读的Markdown格式。其核心能力在于:
● 保留原文档的结构和格式,包括标题、段落、列表等
● 自动删除页眉、页脚、脚注、页码等元素
● 准确提取图片、表格和公式等多模态内容
● 符合人类阅读顺序的排版格式
● 提供完整的版面信息:包括文档元素分类、区块坐标、页码等多维元数据的中间态JSON文件,为智能文档分析、自动化工作流等场景提供结构化数据支持
MinerU代码公开之后,凭借精准、快速的SOTA效果,媲美甚至超过商业软件的性能,获国内外多个技术大V点赞,GitHub Star已突破2.9万,多次登顶GitHub Python Trending,是文档预处理中一个亮眼的开源工具。
二、CAMEL-AI 多智能体协作的开拓者
CAMEL-AI (https://www.camel-ai.org)是一个致力于构建基于大语言模型(LLMs)的多智能体系统的开源平台,其提出的CAMEL框架是最早基于 ChatGPT的autonomous agents的知名项目,已被 NeurlPS 2023录用。该框架通过模块化设计实现多智能体协作。
三、使用方式
你只需三步即可在 CAMEL-AI 框架“工具”、“数据加载器”2个模块轻松调用 MinerU:
1. 首先通过MinerU官网申请API密钥(Token),申请地址:https://mineru.net/apiManage/docs
2. 随后通过CAMEL-AI的extract_url接口,向MinerU提交文档URL并自动获取任务ID(task_id):
def extract_url(self, url: str) -> Dict:
r"""Extract content from a URL document.
Args:
url (str): Document URL to extract content from.
Returns:
Dict: Task identifier for tracking extraction progress.
"""
endpoint = f"{self._api_url}/extract/task"
payload = {"url": url}
try:
response = requests.post(
endpoint,
headers=self._headers,
json=payload,
)
response.raise_for_status()
return response.json()["data"]
except Exception as e:
raise RuntimeError(f"Failed to extract URL: {e}")(extract_url接口代码示意,左右滑动查看)
3. 获得这两项凭证后,开发者可在CAMEL框架的工具模块直接调用MinerU的RESTful API进行文档解析请求提交;也可以在数据加载器模块通过MinerU Client类实时获取结构化数据流。
完整代码链接:
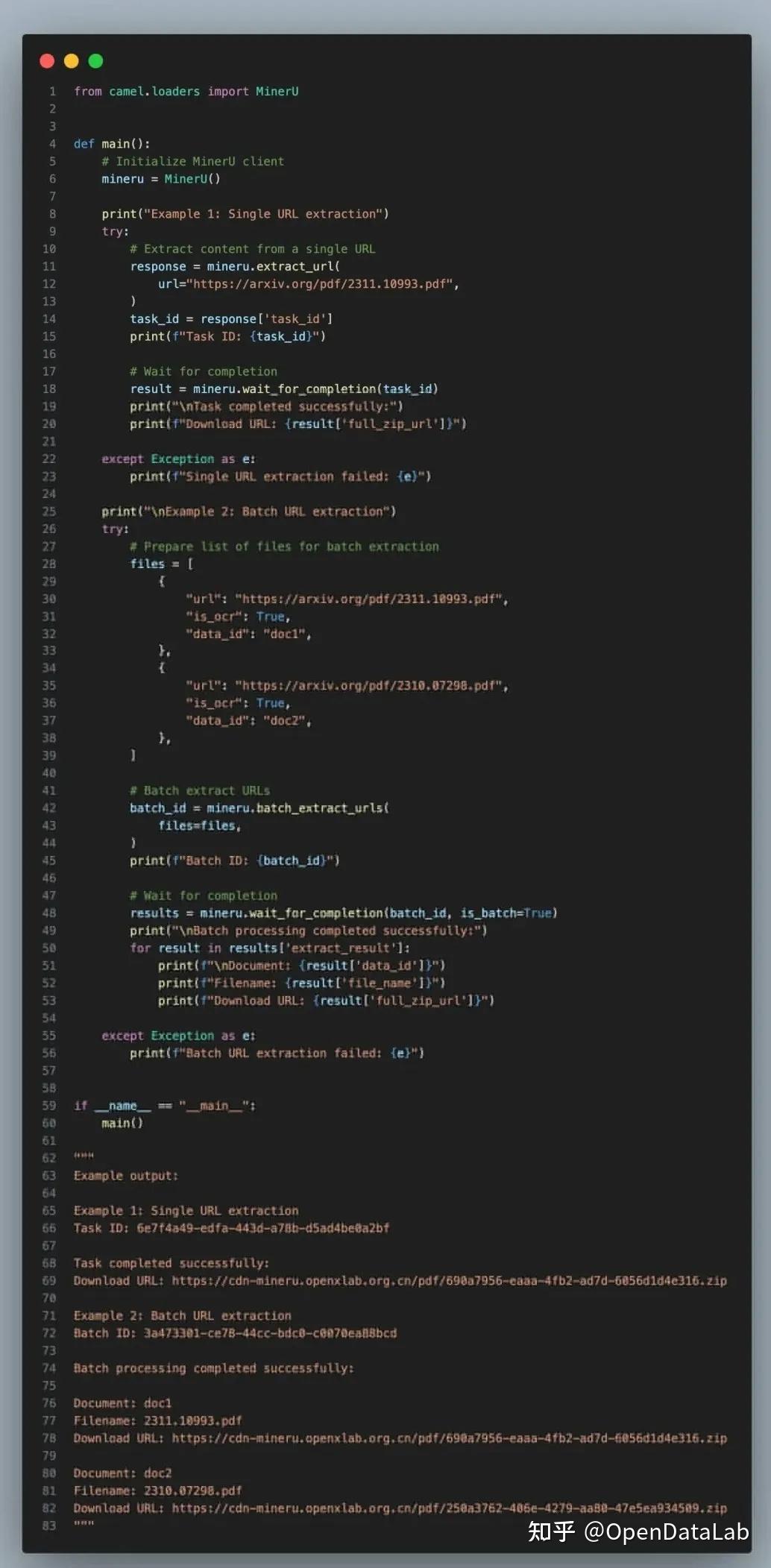
(CAMEL-AI 框架中“数据加载器”模块,调用MinerU代码示例)
四、灵活的智能体应用
在这样轻便、灵活、工具丰富的框架里,你能够通过简单的几行代码开发自己的智能体,构建支持多模态文档协同的智能体系统。
例如在金融合同审查场景中,可以在CAMEL-AI创建法律智能体,自动触发MinerU的表格提取功能,将PDF条款转化为Markdown格式并注入多智能体协作流程,整个过程无需人工干预即可完成端到端解析与决策。
还有更多好玩的功能等你探索,快来申请 MinerU API服务吧:
‣