type
status
date
slug
summary
tags
category
icon
password
目前找到的很多资料都是现有纸质出版物,再有扫描电子版。而这个扫描版pdf文件的向量化解析是个难点。在上一篇文章的最后,我上传了一份47MB的《义务教育教科书数学四年级下册.pdf》至Dify知识库中,识别效果(召回测试)很差。
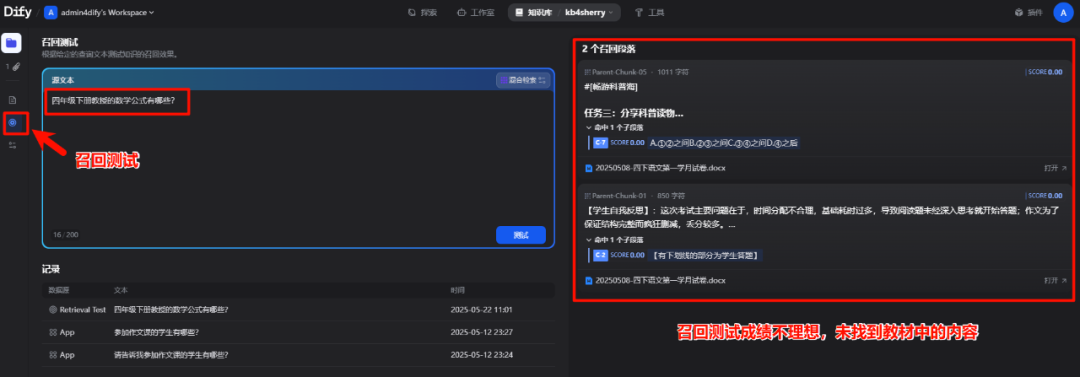
原本问知识库的问题是“四年级下册教授的数学公式有哪些?”,希望AI从已上传的数学书教材中总结回答,结果召回测试的结果却是从不相干的文档中找答案。这也说明该教材pdf文件没有被知识库大模型的向量解析识别到。通过分析市面上开源免费效果好的解决办法,找到了MinerU这款国内的开源软件来对扫描版pdf文件做预处理后再上传Dify知识库。
MinerU的官方网址:“https://mineru.net/”
MinerU在GitHub上的地址:“https://github.com/opendatalab/MinerU”
MinerU就是一款一站式开源高质量数据提取工具,它可以将PDF转换成机器可读的Markdown和JSON格式。 MinerU诞生于“书生·浦语”(“https://github.com/InternLM/InternLM”) 的预训练过程中,MinerU将会集中精力解决科技文献中的符号转化问题,目前GitHub上最新版本是“magic_pdf-1.3.11-released”。
一、MinerU的主要功能:
MinerU的主要功能如下所示:
- 删除页眉、页脚、脚注、页码等元素,确保语义连贯
- 输出符合人类阅读顺序的文本,适用于单栏、多栏及复杂排版
- 保留原文档的结构,包括标题、段落、列表等
- 提取图像、图片描述、表格、表格标题及脚注
- 自动识别并转换文档中的公式为LaTeX格式
- 自动识别并转换文档中的表格为HTML格式
- 自动检测扫描版PDF和乱码PDF,并启用OCR功能
- OCR支持84种语言的检测与识别
- 支持多种输出格式,如多模态与NLP的Markdown、按阅读顺序排序的JSON、含有丰富信息的中间格式等
- 支持多种可视化结果,包括layout可视化、span可视化等,便于高效确认输出效果与质检
- 支持纯CPU环境运行,并支持 GPU(CUDA)/NPU(CANN)/MPS 加速
- 兼容Windows、Linux和Mac平台
二、Windows11本地安装MinerU软件本体
由于我的Dify需要连接MinerU的web API,咨询过MinerU官方同学,明确几个容易混淆的概念:
- 是不是安装“Windows版MinerU客户端”软件就能使用web API了?
其实不是的,“Windows版MinerU客户端”软件真的就是一个“客户端”,它使用的是MinerU云端的算力。但端没有开放接口,无法与web API连接。
- MinerU的web API使用的是云端算力?或者本地MinerU算力?
官方回复“当然是MinerU本地算力”。所以需要先在Windows11本地安装MinerU软件本体。
Windows10/11本地安装MinerU软件本地的官方指南链接如下:
1、安装cuda环境
先检查自己的cuda版本。使用MobaXterm登录到“Ubuntu24.04”这个默认WSL环境中,通过如下命令检查自己的设备是否支持在docker上使用CUDA加速。
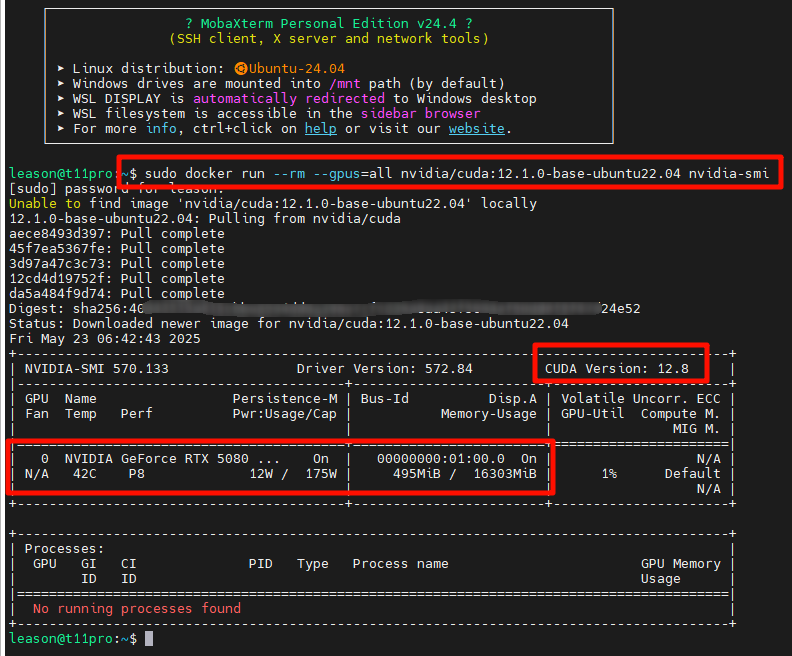
上图可见,一开始也没有在本地找到“nvidia/cuda:12.1.0-base-ubuntu22.04”的镜像,然后就自动下载了最新CUDA镜像,版本到了12.8;并且显示了本地GPU的型号和显存容量。
注意:MinerU官方要求“Windows10/11+GPU方式运行Docker形态MinerU需设备GPU显存大于等于6GB,默认开启所有加速功能”。
由于官网的docker安装cuda环境的命令一直报错,所以改为Windows本地直接安装MinerU软件。
需要安装符合torch要求的cuda版本,具体可参考torch官网:
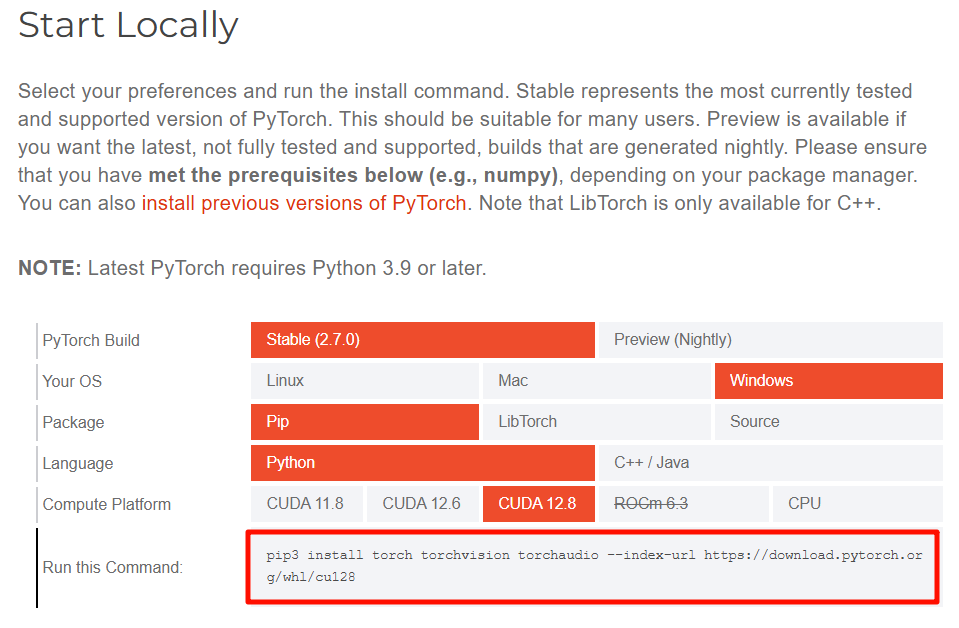
本地Windows使用“管理员”权限打开“PowerShell”命令行,先使用命令检查本地是否已经安装pip环境:

然后输入上述安装cuda的命令行:
整个PyTorch的安装包蛮大的,3个多GB,安装成功。
2、安装anaconda
如果已安装conda,可以跳过本步骤。
亲测发现一个bug,MinerU官方提供的Anaconda(Anaconda3-2024.06-1-Windows-x86_64.exe)清华站点的下载链接已经失效,被清华屏蔽了:
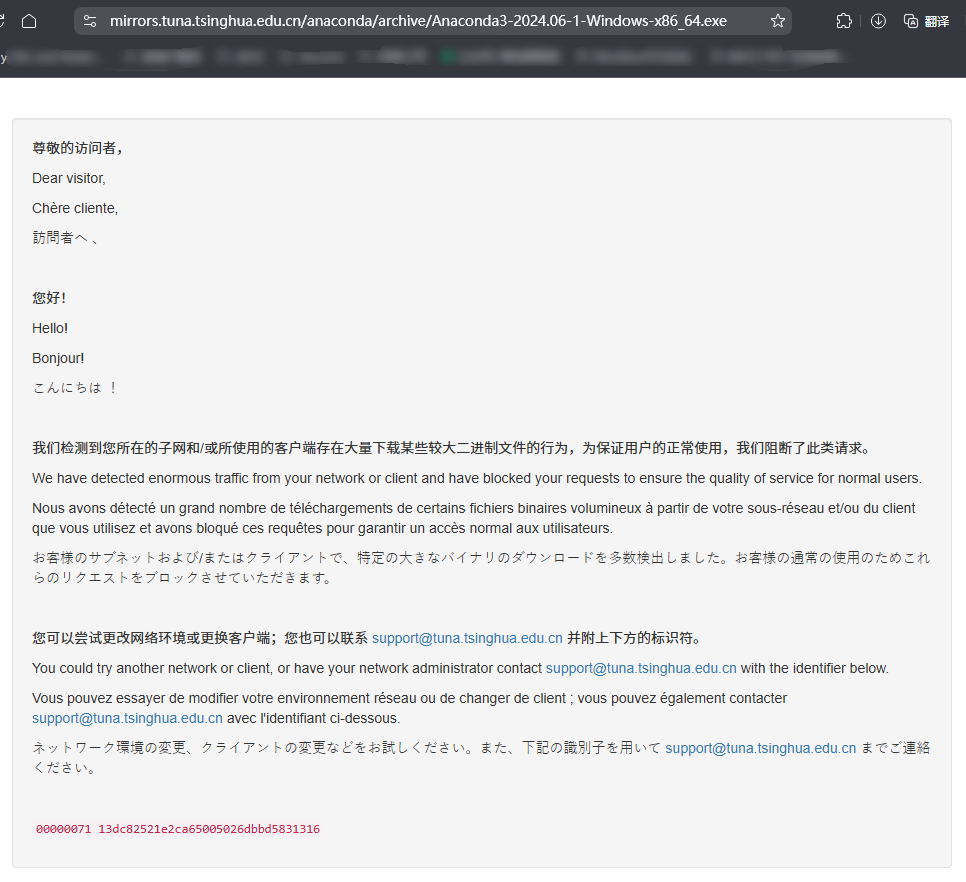
我从官方网站下载了“Anaconda3-2024.10-1-Windows-x86_64.exe”版本,有需求的朋友,关注本公众号之后,后台私信“anaconda”即可收到回复。
下载完成后就图形界面的一路next安装完毕即可。
3、使用conda创建环境
在原先的PowerShell中使用conda命令报错:

需要启动刚刚安装完毕的“Anaconda Navigator”,并在界面上点击“anaconda_powershell_prompt”的启动(Launch)按钮。
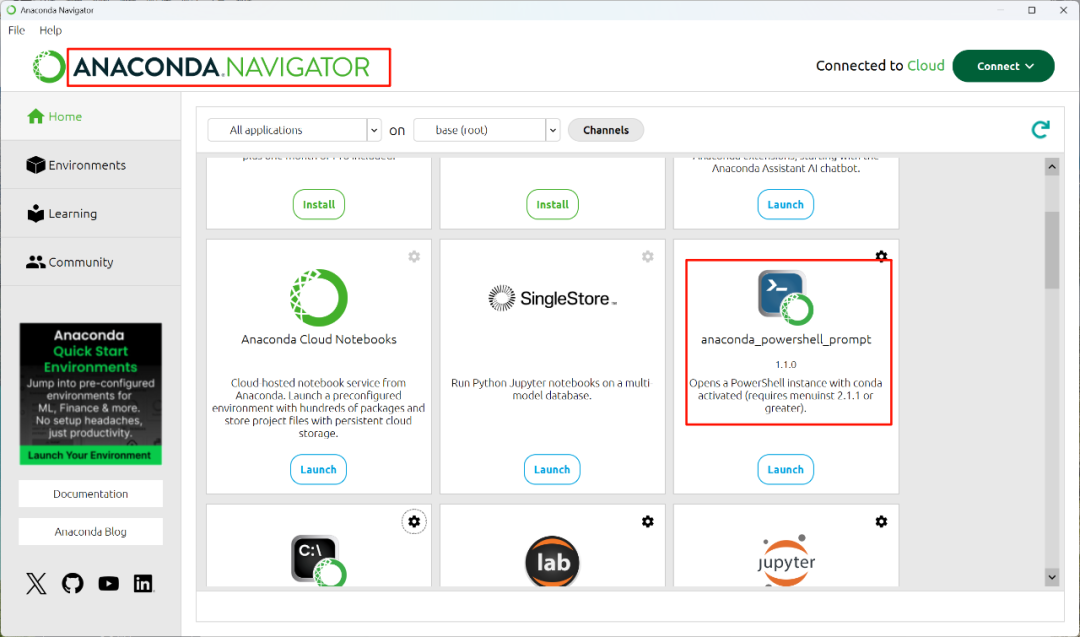
在Anaconda的PowerShell中执行如下命令行创建MinerU环境:
这里特别注意:官方代码中“python=3.12”,我就记得前面我查过Python的版本是3.13,所以这里大家需要根据自己的具体版本号去修改代码。

运行成功后就激活“MinerU”的Python环境:
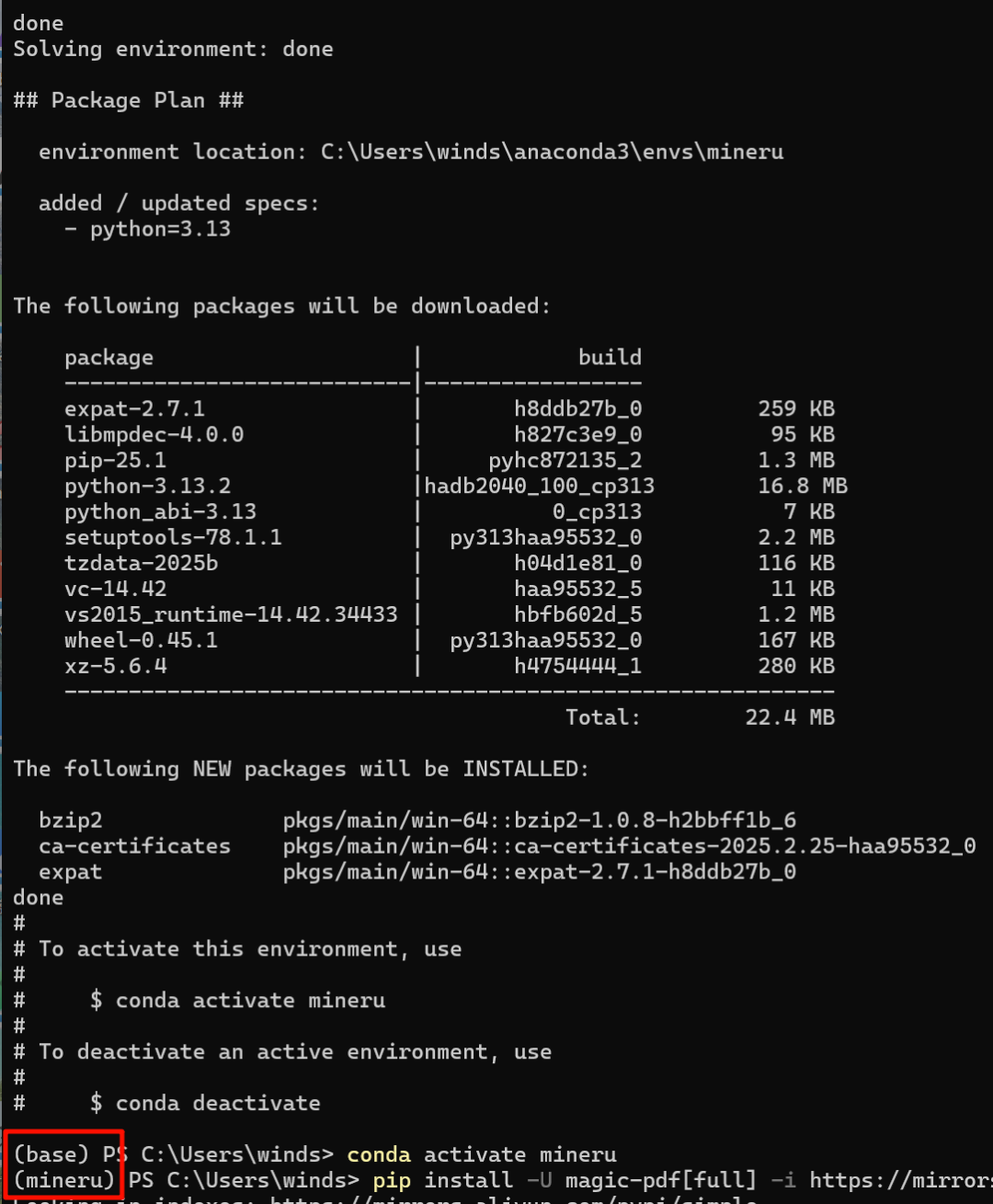
激活后命令行的前缀会由“(base)”变为“(mineru)”。
4、安装应用
继续在Anaconda的PowerShell中执行如下命令:
下载完成后,您可以通过以下命令检查magic-pdf的版本:

由上述操作可知,magic-pdf的版本是1.3.12
5、下载模型并查看配置文件
下载模型的官方指南:【“https://github.com/opendatalab/MinerU/blob/master/docs/how_to_download_models_zh_cn.md”】
模型下载分为首次下载和更新模型目录,请参考对应的文档内容进行操作。此处我是首次下载模型。模型文件可以从 Hugging Face或ModelScope下载,由于网络原因,国内用户访问HF可能会失败,请使用 ModelScope。
使用python脚本从ModelScope下载模型文件:
python脚本会自动下载模型文件并配置好配置文件中的模型目录,配置文件可以在用户目录中找到,文件名为magic-pdf.json;本次安装的modelscope的版本号是1.26.0。
如果此前下载过模型,可以重复执行此前的模型下载python脚本,将会自动将模型目录更新到最新版本。
完成“下载模型”步骤后,脚本会自动生成用户目录下的magic-pdf.json文件,并自动配置默认模型路径。 您可在【"C:/Users/用户名"】下找到magic-pdf.json文件。并用“文本文件”编辑器打开即可查看内容。
6、安装LibreOffice以支持doc等文档格式解析
在Windows上下载并安装libreoffice软件,国内镜像下载地址是:“https://mirrors.cloud.tencent.com/libreoffice/libreoffice/stable/”。安装完毕之后,需要在“系统环境变量”的变量“Path”中添加libreoffice的安装路径“install_dir\LibreOffice\program”(我的是“C:\Program Files\LibreOffice\program ”)进入系统环境变量。
7、第一次运行MinerU
从仓库中下载样本文件,并测试:
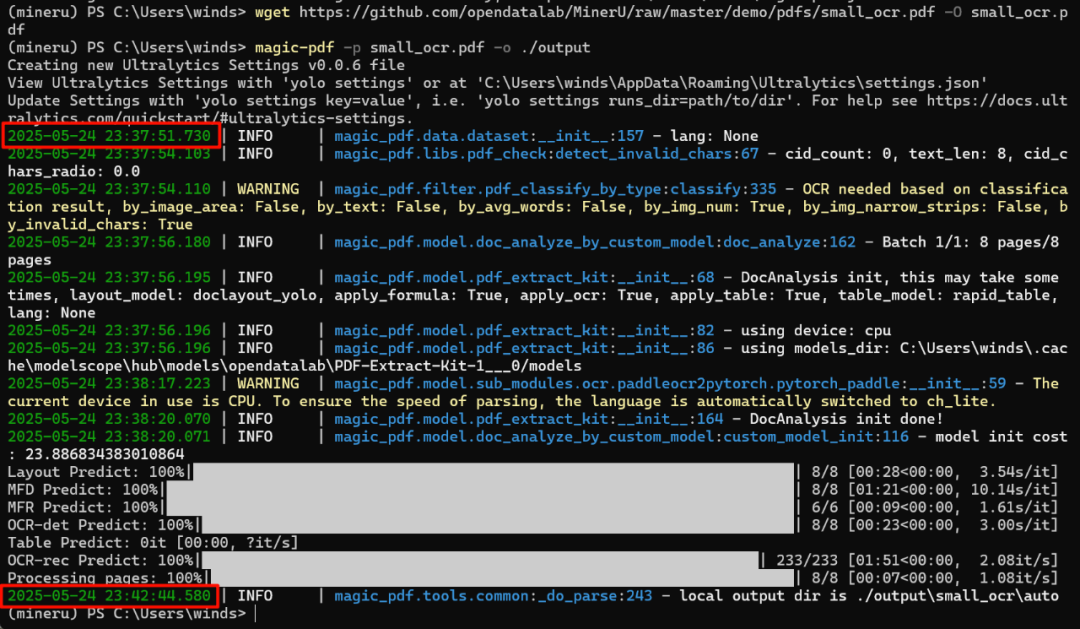
以上是执行转换命令的耗时。
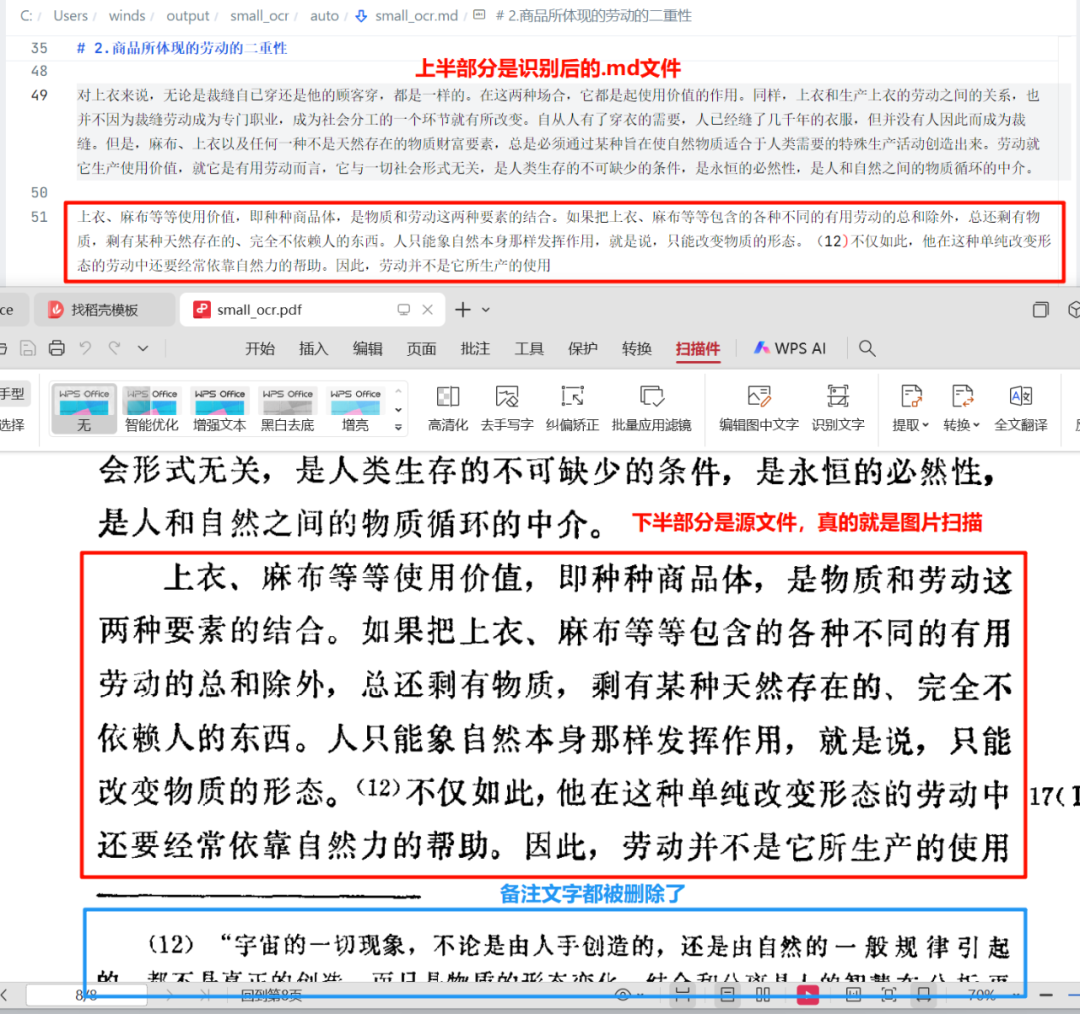
从MinerU识别出来的Markdown格式文件来看,把“题头”和“题尾”信息都删除掉,识别还是非常准确的。
8、测试CUDA加速
如果您的显卡显存大于等于 6GB ,可以进行以下流程,测试CUDA解析加速效果:
覆盖安装支持cuda的torch和torchvision(请根据cuda版本选择合适的index-url,具体可参考torch官网),我使用的是如下命令:
“--index-url”中的链接就是第1步安装CUDA环境时用的链接。并且要在使用“管理员账户”运行的PowerShell中去运行上述命令。
修改【用户目录】中配置文件magic-pdf.json中"device-mode"的值
{ "device-mode":"cuda"}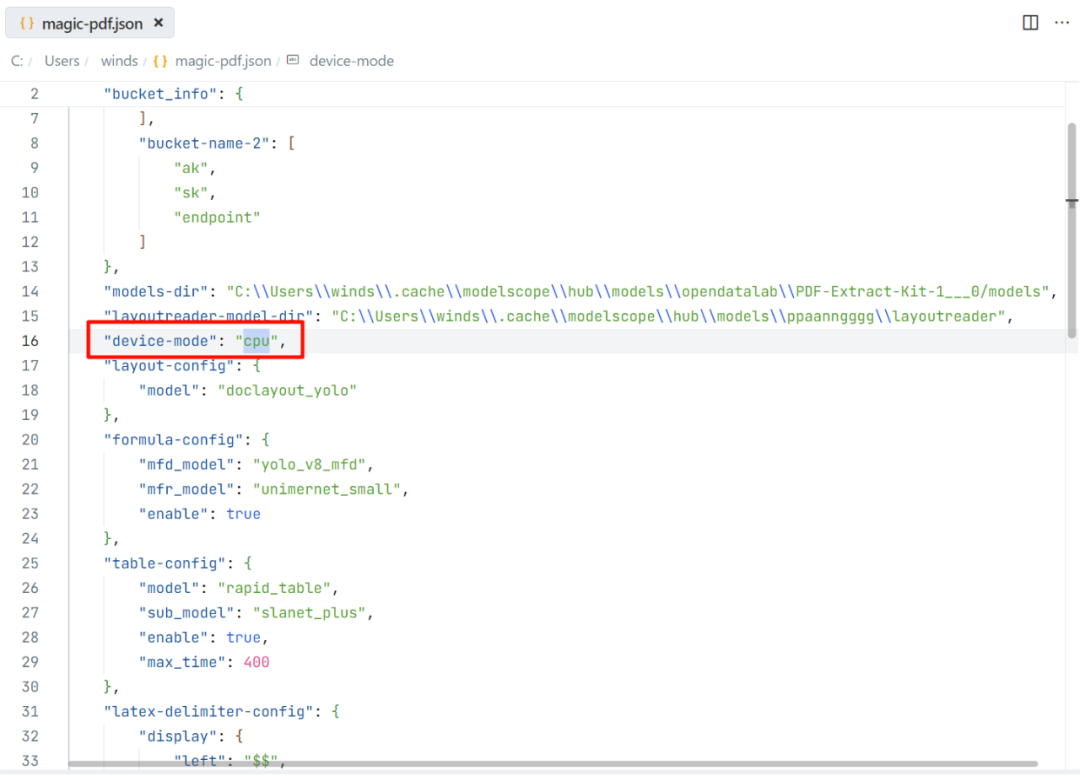
运行以下命令测试cuda加速效果:
【报错】信息如下:
File "C:\Users\winds\anaconda3\envs\mineru\Lib\site-packages\torch\cuda\__init__.py", line 363, in _lazy_init
raise AssertionError("Torch not compiled with CUDA enabled")
AssertionError: Torch not compiled with CUDA enabled
要解决这个问题,只有将PyTorch重新结合CUDA做编译。先用如下命令卸载Torch框架(包含torch和torchvision):
然后重新安装Torch框架并确保使用CUDA进行编译,使用如下命令:
(注意:此处的cu128,需要根据自己具体的CUDA版本填写,这里是12.8版本)
再次测试,仍然报错,也就是使用cuda加速失败。只有先用cpu来做解析用着吧。
三、测试MinerU预解析的效果
在Windows11桌面启动“Anaconda Navigator”,进入“Environments”,选择“mineru”启动命令行的MinerU环境:
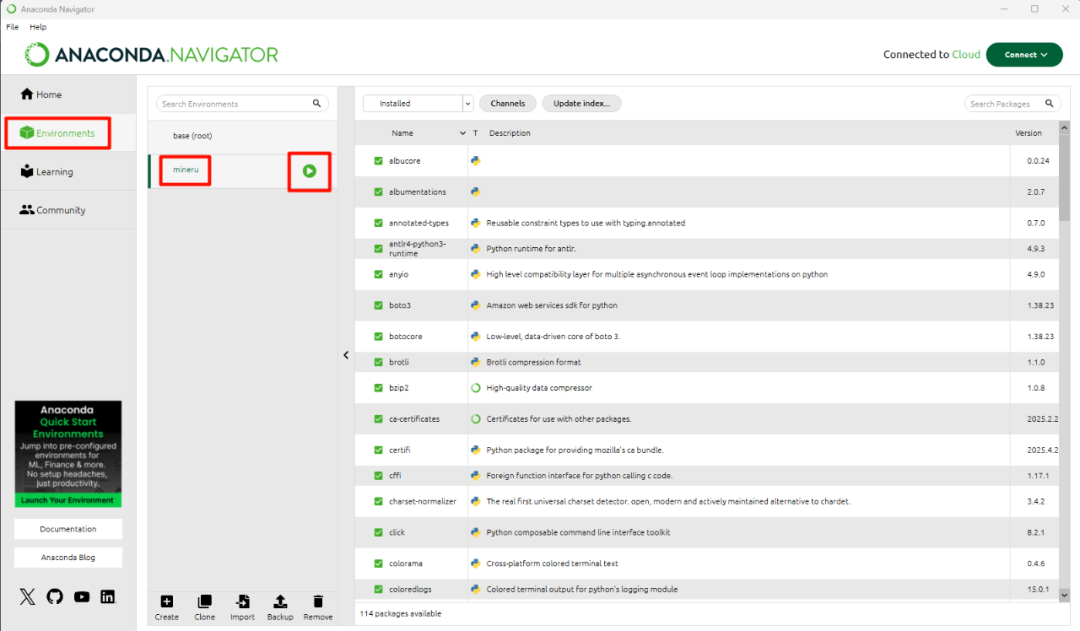
使用命令行:
执行完后,就会在该目录下的“output”文件夹下产生一个“义务教育教科书·语文四年级下册”文件夹,其中包含包含对应的Markdown文件、以及语义识别出来的“layout”和“spans”pdf版本。
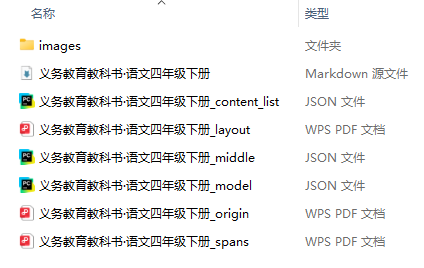
将整个文件夹导入Dify自带知识库中。
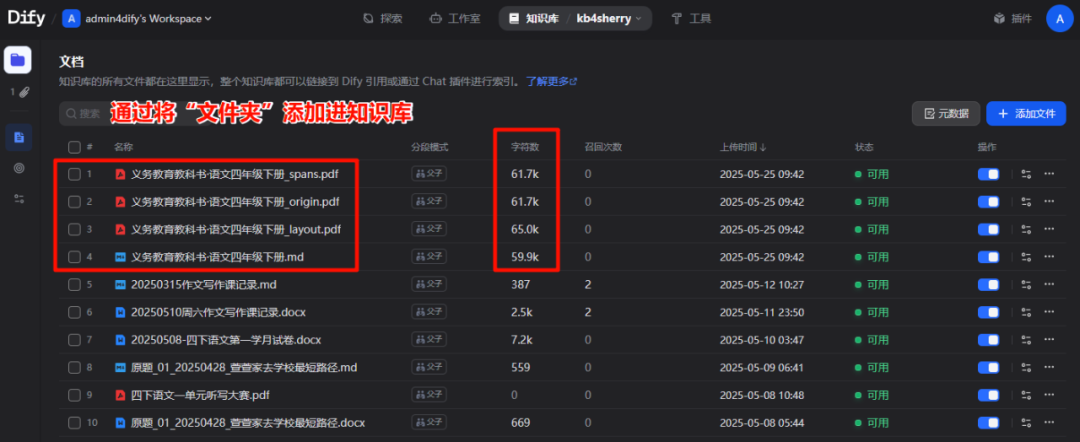
进行分段处理后,文档就能识别到“字符数”,然后开始“召回测试”。
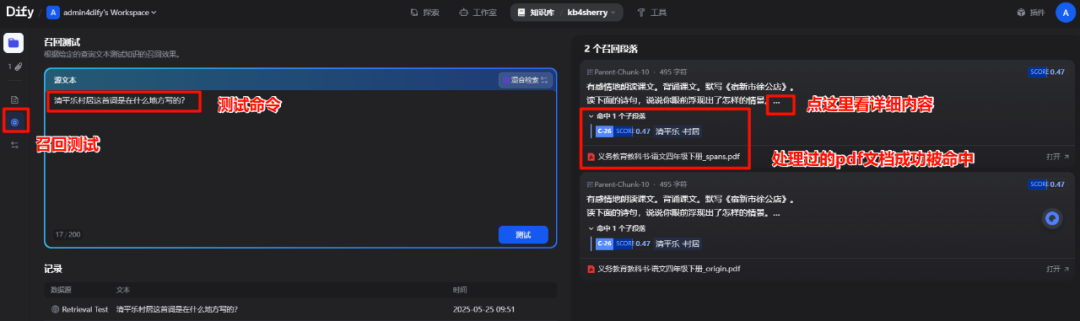
“召回测试”的提示词问题是“清平乐村居这首词是在什么地方写的?”,然后准确的从知识库中找到了《义务教育教科书·语文四年级下册_spans.pdf》文件。

在详情中看到召回的段落中出现了本首词的写作地的准确信息。召回准确,成功。
(全文完)
我的文章里面配的一步一步操作的截图比较多,内容稍微偏浅显易懂一点,主要是考虑到“工具就是拿来用的,越多普通人知道如何使用,才能提高效率”,会更多照顾到普通人的理解水平。各位技术大拿可忽略……